Cтуденческий практикум МГТУ им. Н.Э.Баумана по обработке и визуализации графов
Московский государственный технический университет им. Н.Э.Баумана, 31 октября - 4 декабря 2022
- Аннотация
- 1. Графы знаний
- 2. Структура микропроцессора Леонард Эйлер и вычислительного комплекса Тераграф
- 2.1. Набор команд дискретной математики
- 2.2. Структура вычислительного комплекса Тераграф
- 2.3. Микроархитектура гетерогенного ядра обработки графов
- 2.4. Принципы взаимодействия микропроцессора Леонард Эйлер и хост-подсистемы
- 2.5. Библиотека leonhard x64 xrt
- 2.6. Взаимодействие CPE(riscv32im) и SPE(lnh64)
- 3. Практакум №1. Разработка и отладка программ в вычислительном комплексе Тераграф с помощью библиотеки leonhard x64 xrt
- 4. Практикум №2. Обработка и визуализация графов в вычислительном комплексе Тераграф
- 4.1. Конвейер визуализации графов
- 4.2. Представление информационных моделей алгоритма в виде структур данных
- 4.3. Использование библиотеки шаблонов leonhard-x64-xrt-v2 для обработки графов
- 4.4. Примеры реализации алгоритмов на графах
- 4.5. Сборка и запуск проекта
- 4.6. Индивидуальные задания
- 5. Командный практикум. Обработка и визуализация графов в вычислительном комплексе Тераграф
- Конкурсные работы
- Граф решетки
- Гипотеза_Колатца
- Сообщества патентных классов
- Вагапоиды
- Звезда Смерти
- Новогодний лес Левенштейна
- Структура модели личности человека
- История развития вселенной
- Денежные транзакции
- Граф соавторства научных публикаций
- Вселенная адаптационного синдрома Ганса Селье
- Kloube la romantique
- Сцена охоты коронавируса
- Температура финансового рынка
- Доверие
- Звездопад
- Ярославль, социальные связи
- Солнечный Паттерн
- Мы живем в обществе
- Связь между документами
- Одуванчики
- Colloquium_Cum_Comes
- Аномалии в отзывах
- Универы
Руководители практикума
 |
 |
 |
 |
 |
|---|---|---|---|---|
| Алексей Попов, МГТУ им. Н.Э.Баумана |
Станислав Ибрагимов МГТУ им. Н.Э.Баумана |
Егор Дубровин МГТУ им. Н.Э.Баумана |
Ли Цзяцзянь МГТУ им. Н.Э.Баумана |
Михаил Гейне МГТУ им. Н.Э.Баумана |
Эксперты
 |
 |
 |
 |
 |
|---|---|---|---|---|
| Кирилл Лукунин Сбербанк РФ |
Андрей Пономарев МГТУ им. Н.Э.Баумана |
Владимир Савостьянов МГТУ им. Н.Э.Баумана |
Константин Горбунов НИИ Системной биологии и медицины Роспотребнадзора |
Анастасия Рикунова Первый МГМИ им. И.М.Сеченова |
Аннотация
Всем участникам предоставляется доступ к вычислительному комплексу Тераграф для реализации проекта обработки и визуализации графов.
В ходе практикума студенты знакомяться с различными аспектами представления информации в виде графов, их обработкой и визуализацией. Приводится структура вычислительного комплекса Тераграф, микропроцессора Леонард Эйлер и структура гетерогенного ядра обработки графов, а также особенности их программирования. Приводятся примеры инициализации графов в памяти ядра обработки графов, алгоритмов обработки и создания структур для визуализации.
На основе изложенных сведений необходимо разработать распределенное приложение обработки и визуализации графов, функционирующее в системе Тераграф.
Практикум состоит из трех этапов:
-
Исследование микропроцессора Леонард Эйлер
-
Практикум по программированию гетерогенного вычислительного узла
-
Командная разработка алгоритмов обработки и визуализации графов
1. Графы знаний
1.1. Актуальность создания эффективных программных и аппаратных средств обработки графов
Граф G(V,E) – множество вершин V, на элементах которого определены двуместные отношения смежности (ребра) – (vi, vj) ∈ E, где vi, vj ∈ V (обратите внимание на наличие скобок в первом выражении и их отсутствие во втором). Тогда пара вершин, находящихся в отношении смежности, рассматривается как ребро ek = (vi, vj), ek ∈ E. Вершина vi смежна вершине vj тогда и только тогда, когда существует ребро ek, инцидентное vi, такое, что vj инцидентно ему. Аналогично ребру ek смежно ребро el тогда и только тогда, когда существует вершина vi, инцидентная ребру ek, такая, что el инцидентно этой вершине.
Существует несколько видов графов, отличающихся свойствами предикатов инцидентности – неориентированные, ориентированные, гипер- и ультраграфы, метаграфы.
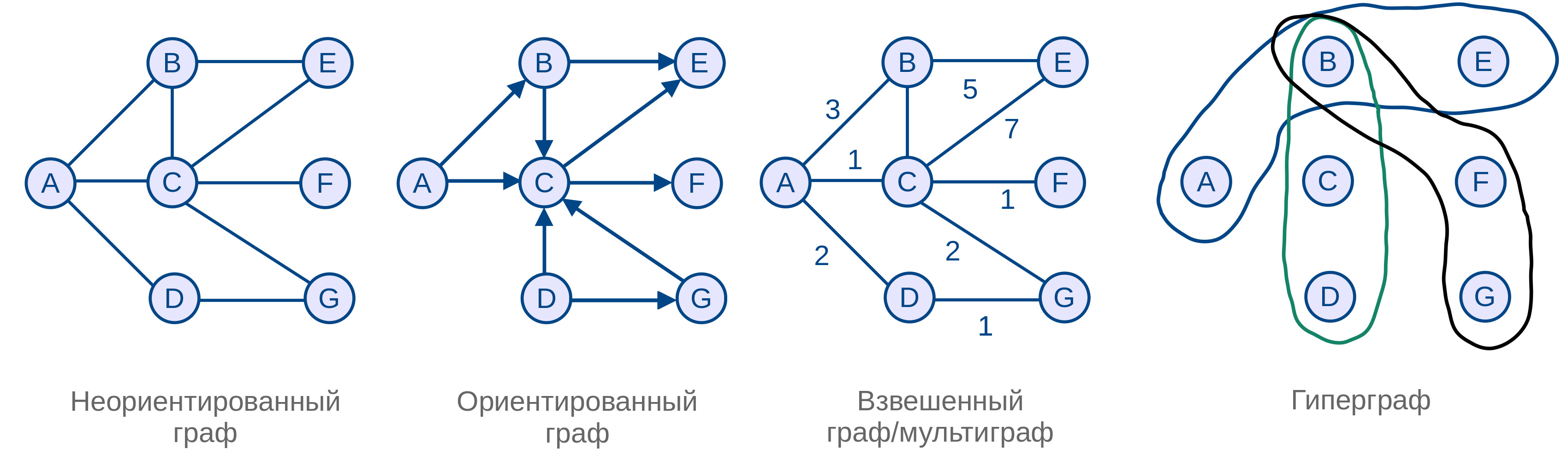 Рисунок 1 — Виды графов
Рисунок 1 — Виды графов
Графы знаний являются способом представления модели знаний в виде графовой структуры. Технологии представления и обработки знаний в виде графов приобрели большое значение во многих областях, в которых другие методы показали низкую эффективность. Благодаря способности сохранять информацию о различных объектах и явлениях и учитывать связи между ними, графы знаний могут использоваться при анализе больших данных в биоинформатике [1], в персонифицированной медицине, системах безопасности городов [2][3][4][5][6], в компьютерных сетях, финансовом секторе, при контроле сложного промышленного производства, для анализа информации социальных сетей и во многих других областях.
Существенное влияние на эффективность применения аппаратных средств в задачах обработки графов оказывает адекватность их применения в рамках парадигмы рассматриваемых вычислений. Так, ряд задач обработки графов основан на статических графах, изменение которых либо не предусматривается вообще, либо происходит за пределами графового вычислителя. Для такого класса задач обработки графов характерным является этап передачи графа из исходного места хранения в оперативное хранилище графового вычислителя или же потоковая обработка. Подобная обработка позволяет применять классические варианты построения вычислительных систем, в которых передача данных происходит большими или непрерывными пакетами, а останов ритмичной обработки не предусматривается спецификой алгоритмов. Для решения данного класса задач хорошо зарекомендовали себя графические ускорители GPU [7] и матрично-конвейерные структуры на ПЛИС [8]. Второй вариант постановки задач обработки графов отличается тем, что информация графа должна меняться как под воздействием внутренней обработки (например, результата поиска кратчайшего пути или центральных вершин), так и под воздействием внешних факторов (запросов на изменение информации графов). В этом случае граф должен находится непосредственно в оперативной памяти (памяти процессора общего назначения или специального устройства обработки графов). Такой вариант предполагает непрерывность процессов обработки и изменения, что приводит к необходимости применения иных архитектурных принципов. Вычислительные средства, эффективно воплощающие подобную функциональность, опираются на оптимизацию алгоритмов доступа к структурам данных и графам в памяти, на повышение эффективности подсистемы памяти, на увеличение степени параллельности при обработке каждой нити вычислений.
Приведенные выше различия статических и динамических задач обработки графов приводят к тому, что несмотря на большое количество и разнообразие средств вычислительной техники, потребность в высокопроизводительных ЭВМ для решения задач обработки графов знаний, чрезвычайно высока. При решении подобных задач дальнейшее увеличение скорости обработки на основе универсальных микропроцессорных систем трудно достижимо. Даже благодаря высокому уровню параллелизма, глубокой конвейеризации и большим тактовым частотам современные микропроцессоры и графические ускорители не способны эффективно решать проблемы обработки больших графов. Сказываются такие фундаментальные проблемы, как: зависимости по данным [9][10]; необходимость распределения вычислительной нагрузки при обработке нерегулярных графов; наличия конфликтов при доступе к памяти большого количества обрабатывающих ядер [11].
В МГТУ им. Н.Э.Баумана в настоящее время создается вычислительный комплекс, предназначенный для обработки графов и обладающий передовыми техническими характеристиками: аппаратная реализация набора команд дискретной математики, гетерогенная архитектура, хранение и обработка до 1 триллиона вершин графа. В ходе практикума все участникам будет предоставлен доступ к одной карте комплекса Тераграф.
1.2. Применения графов в задачах аналитики данных и искусственном интеллекте
Безусловным достижением последнего десятилетия является внедрение систем анализа данных на основе алгоритмов и методов машинного обучения. Эти технологии позволяют решить одну из важнейших задач: выявление фактов из огромного потока данных. Следующим звеном в цепи интеллектуального анализа данных должна быть система, способная хранить и обрабатывать найденные факты и связи между ними в виде графов знаний (Рисунок 2).
 Рисунок 2 — Аналитическая система на основе графов знаний
Рисунок 2 — Аналитическая система на основе графов знаний
Уже сейчас оказывается недостаточным просто хранить огромные массивы фактов и извлекать их по запросу. Необходимо иметь систему, способную анализировать причинно-следственные связи между событиями, оценивать достоверность и полноту сведений, выявлять и хранить контекстную информацию. Именно графы позволяют получать ответы на те вопросы, которые интересуют пользователя такой системы. Например, насколько вероятно развитие дорожной обстановки по неблагоприятному сценарию и как его избежать, имеют ли место незаконные финансовые операции, кто в них задействован и какие схожие сценарии возможны? При этом подход к формированию ответов на такие вопросы должен принципиально отличаться от простого поиска ситуаций похожих на те, что система видела раньше (как это делается сейчас в нейронных сетях). Аналитическая система будущего должна не просто искать сходства и различия, но уметь логически рассуждать на основе графов знаний. В этом смысле, все известные системе факты и правила будут использоваться для принятия решения. Использование логического вывода на основе графов способно избавить аналитическую систему от ошибок, связанных с игнорированием контекста и здравого смысла, и, главное, делает результат объяснимым.
Рисунок 3 — Примеры графов знаний
Важность повышения эффективности алгоритмов на графах и совершенствования вычислительных средств для их реализации привели к появлению такого направления как Graph Data Science. Это подразумевает выделение в отельную научную область интересов всего, что связано с аналитикой данных с использованием графов. В набор средств анализа входят такие алгоритмы, как: обнаружение сообществ в графах, центральность, поиск подобия и изоморфизм, поиска кратчайших путей и максимальных потоков, и ряд других. Приведем некоторые примеры применения графовых алгоритмов для решения важных практических задач.
Обнаружение незаконных финансовых операций
Мошенники делят грязные деньги на множество малых частей и смешивают их с законными средствами, и затем превращают их в легальные активы. Для этого используется круговое движение денежных средств, которое скрывает первоначальный источник за длинной цепочкой транзакций. Графы позволяют построить модель движения денег для таких мошеннических схем и своевременно препятствовать им.
Обнаружение финансового мошенничества в реальном времени
Все банки стремятся ускорить доступ клиентов к услугам и денежным переводам, что представляет собой потенциальную опасность. Необходимо анализировать множество факторов, сопровождающих транзакцию: местоположение клиента и ip адрес устройства; расстояние до предыдущего места нахождения клиента и время, прошедшее с этого момента; номер карты и счета клиента; история расходов клиента по карте и многое другое. Эти данные формируют графовую структуру, позволяя банку оценить отношения событий и имеющихся в его распоряжении данных.
Контроль мошеннической деятельности в налоговой сфере
Системы налогообложения и выявление неуплаты налогов должны постоянно совершенствоваться, чтобы учитывать новые способы ухода от уплаты налогов и мошеннические схемы. С повышением доступности предпринимательства и автоматизацией бизнес-деятельности у преступников появились дополнительные возможности создания подставных юридических лиц, через которых передаются незаконно полученные денежные средства. Графы позволяют анализировать сложные схемы использования подставных юридических лиц и обнаружить мошенническую схему по структуре и взаимосвязи субъектов, участвующих в бизнес-деятельности. Подозрительные паттерны быстро обнаруживаются и выявляются структурные закономерности, которые позволяют установить единый центр мошеннической деятельности.
Промышленное производство и контроль жизненного цикла оборудования
Современное промышленное производство основано на длинных цепочках поставок. При этом сроки поставок и жизненный срок изделий различных поставщиков может отличаться. Если представить масштабы работы таких технически сложных объектов, как энергосеть региона или даже страны, становится понятным сложность планирования и модернизации их работы. Необходимо учесть взаимное влияние возможных отказов оборудования, сложность и стоимость их замены, гарантийный срок службы и т.д. Графы позволяют создать модель таких сложных систем и осуществлять управление ими.
Персонифицированная медицина
Графы хорошо подходят для хранения и визуализации медицинской информации. Данные о состоянии организма пациента являются взаимосвязанными, и могут быть соотнесены с аналогичными данными других пациентов. Компания AstraZeneca провела успешные исследования, в которых граф знаний об организме одного члена “сообщества” использовался при выборе терапии для больного по аналогии с другими подобными случаями.
Биомедицинские исследования
Цепочки химических реакций также представимы в виде графов, в связи с чем в биологии и биомедицине стоит проблема моделирования подобных структур. Обмен веществ в организме человека - это также сеть химических реакций, катализируемых ферментами. В настоящее время изучены более 10 тысяч различных химических реакций, которые происходят в организме для построения клеточных структур. С помощью графов можно описать метаболизм как круговорот атомов, представив в них все реакции с химической структурой небольших соединений (метаболитов). Это, в свою очередь, открывает перед исследователями возможности синтеза новых лекарственных препаратов.
2. Структура микропроцессора Леонард Эйлер и вычислительного комплекса Тераграф
Анализ графов существенно отличается от привычной арифметико-логической обработки. Самыми существенными особенностями алгоритмов обработки графов являются:
-
зависимости по данным между последовательными итерациями поиска и анализа информации
-
большее количество операций доступа к памяти по сравнению с количеством арифметико-логических операций.
Поэтому в МГТУ им. Н.Э.Баумана была разработана гетерогенная архитектура вычислительного комплекса Тераграф, учитывающая особенности обработки графов. Отличительными чертами комплекса являются:
-
Доступ к графам и их обработку осуществляет специализированный микропроцессор
lnh64с набором команд дискретной математики (Discrete mathematics instruction set computer,DISC). -
Оперативное хранилище графов (так называемая
Локальная память структур,Local Structure Memory,LSM) имеет большой размер (2.5 ГБ на один микропроцессорlnh64) и организована как ассоциативная память. -
DISCмикропроцессорlnh64подключен непосредственно к шине памяти малого арифметического процессораriscv32im. Пара процессоровlnh64иriscv32imи составляет гетерогенное ядро обработки графов (Graph Processing Core,GPC). -
Множество гетерогенных ядер обработки графов
GPCсоставляют многоядерный микропроцессорЛеонард Эйлер(также обозначается какStructure Processing Unit,SPU).
Рассмотрим структуру комплекса Тераграф более подробно.
2.1. Набор команд дискретной математики
Ключевым вопросом при проектировании любого программно-управляемого устройства является выбор набора команд. Так как целями создания микропроцессорного ядра lnh64 являются аппаратная поддержка дискретной математики, набор инструкций составлен на основе таких понятий, как кванторы, отношения и операции над множествами.
Таблица 1 – Соответствие инструкций DISC функциям, кванторам и операциям дискретной математики
| Функции, кванторы и операции дискретной математики | Инструкции набора команд DISC |
|---|---|
| Функция хранения кортежа | INS |
| Функция отношения элементов множества | NEXT,PREV,NSM,NGR,MIN,MAX |
| Мощность множества | CNT |
| Функция принадлежности элемента множеству | SRCH |
| Добавление элемента в множество | INS |
| Исключение элемента из множества | DEL,DELS |
| Исключение подмножества из кортежа | DELS |
| Включение подмножества в кортеж | INS,LS,GR,LSEQ,GREQ,GRLS |
| Отношение эквивалентности множеств | INS,LS,GR,LSEQ,GREQ,GRLS |
| Объединение множеств | OR |
| Пересечение множеств | AND |
| Разность множеств | NOT |
Последняя версия набора команд DISC состоит из 21 высокоуровневой инструкции, перечисленных ниже:
-
Search (SRCH) выполняет поиск значения, связанного с ключом.
-
Insert (INS) вставляет пару ключ-значение в структуру. SPU обновляет значение, если указанный ключ уже находится в структуре.
-
Операция Delete (DEL) выполняет поиск указанного ключа и удаляет его из структуры данных.
-
Последняя версия набора команд была расширена двумя новыми инструкциями (NSM и NGR) для обеспечения требований некоторых алгоритмов. Команды NSM/NGR выполняют поиск соседнего ключа, который меньше (или больше) заданного и возвращает его значение. Операции могут быть использованы для эвристических вычислений, где интерполяция данных используется вместо точных вычислений (например, кластеризация или агрегация).
-
Maximum /minimum (MAX, MIN) ищут первый или последний ключи в структуре данных.
-
Операция Cardinality (CNT) определяет количество ключей, хранящихся в структуре.
-
Команды AND, OR, NOT выполняют объединения, пересечения и дополнения в двух структурах данных.
-
Срезы (LS, GR, LSEQ, GREQ, GRLS) извлекают подмножество одной структуры данных в другую.
-
Переход к следующему или предыдущему (NEXT, PREV) находят соседний (следующий или предыдущий) ключ в структуре данных относительно переданного ключа. В связи с тем, что исходный ключ должен обязательно присутствовать в структуре данных, операции NEXT/PREV отличаются от NSM/NGR.
-
Удаление структуры (DELS) очищает все ресурсы, используемые заданной структурой.
-
Команда Squeeze (SQ) дефрагментирует блоки локальной памяти, используемые структурой.
-
Команда Jump (JT) указывает код ветвления, который должен быть синхронизирован с хост CPU (команда доступна только в режиме МКОД при синхронной обработке данных CPU и SPU в составе вычислительного комплекса).
Вызов команд lnh64 осуществляется передачей из микропроцессора riscv32im операндов и кода операции. Результаты выполнения команд сохраняются в регистрах результата (ключ и значение) и регистре статуса. Дополнительно предусмотрена очередь результатов, содержащая аналогичные данные, расположенные последовательно в порядке завершения инструкций. Другим способом передачи результата являются так называемые регистры mailbox.
Механизм ожидания результатов mailbox предполагает наличие регистров, чтение данных из которых возможно только при поступлении в них действительных значений результатов. В случае, если регистр не содержит результатов, чтение из него вызывает ошибку доступа, или же приостанавливает транзакцию на шине. После прочтения, результат регистра mailbox аннулируется (сбрасывается флаг достоврености).
Примеры вызова команд и ожидания результатов будут рассмотрены в практической части работы.
2.2. Структура вычислительного комплекса Тераграф
Комплекс «Тераграф» предназначен для хранения и обработки графов сверхбольшой размерности и будет применяться для моделирования биологических систем, анализа финансовых потоков в режиме реального времени, для хранения знаний в системах искусственного интеллекта, создания интеллектуальных автопилотов с функциями анализа дорожной обстановки, и в других прикладных задачах. Он способен обрабатывать графы сверхбольшой размерности до 1012 (одного триллиона) вершин и 2·1012 ребер. Комплекс состоит из 3-х однотипных гетерогенных узлов, которые взаимодействуют между собой через высокоскоростные сетевые подключения 100Gb Ethernet. Каждый узел состоит из хост-подсистемы, подсистемы хранения графов, подсистемы коммутации узлов, а также подсистемы обработки графов. Структурная схема одного узла представлена на рисунке 4
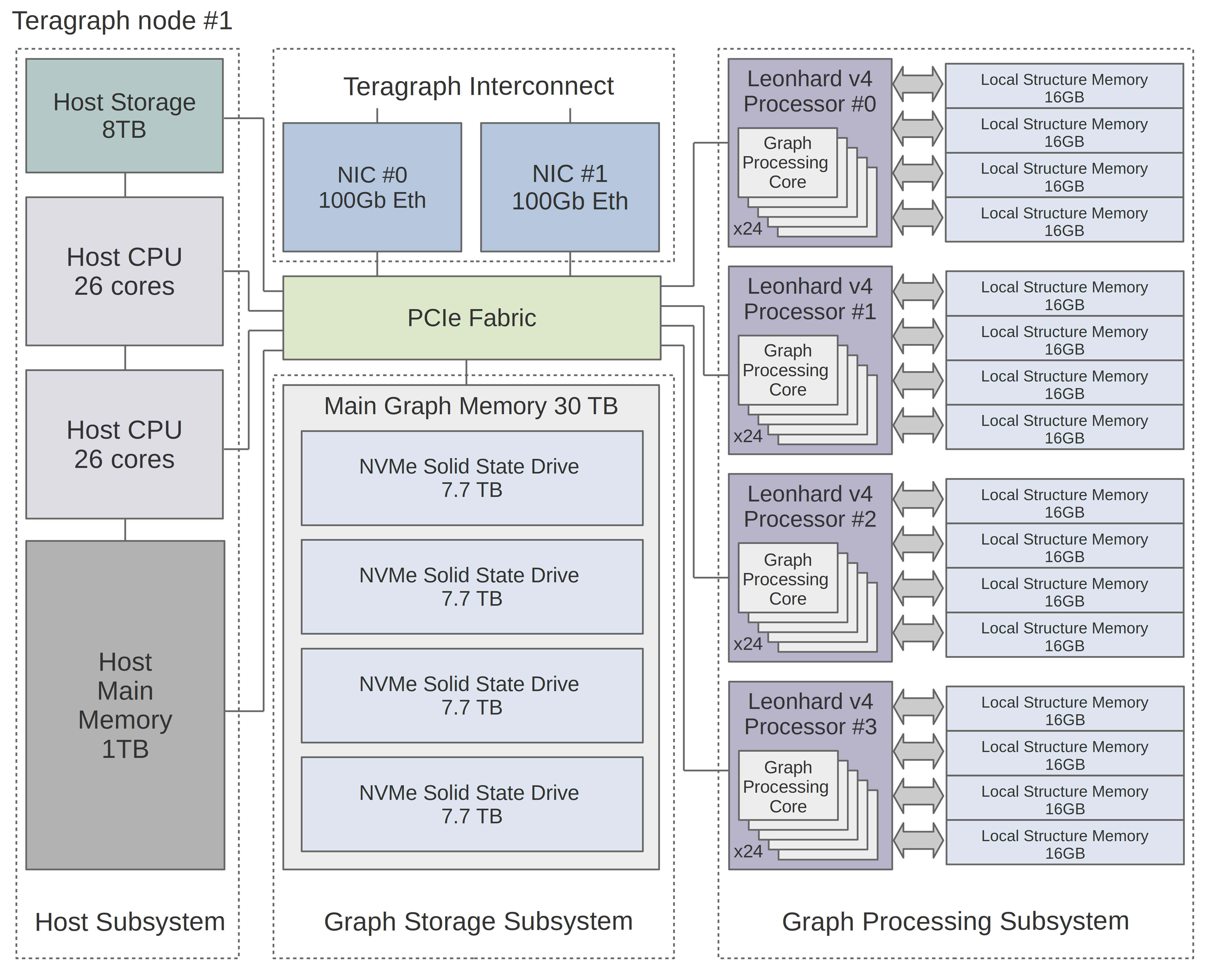 Рисунок 4 — Структура гетерогенного узла
Рисунок 4 — Структура гетерогенного узла
Комплекс Терраграф организован по следующим принципам:
-
для ускорения обмена данными внутри комплекса устройства обработки множеств и структур данных размещаются на одном кристалле с универсальными процессорным устройством;
-
совместно на одном кристалле размещается несколько DISC устройств, которые имеют независимые каналы памяти;
-
несколько гетерогенных вычислительных узлов объединены в единый комплекс высокоскоростными сетевыми интерфейсами, обеспечивающими взаимодействие DISC устройств и подсистемы памяти.
2.2.1. Хост-подсистема
Основная вычислительная системы (так называемая хост-подсистема) берет на себя функции управления запуском вычислительных задач, поддержкой сетевых подключений, обработкой и балансировкой нагрузки. В хост-подсистему входят два многоядерных ЦПУ по 26 ядер каждый, оперативная память на 1 Тбайт и дополнительная энергонезависимая память на 8 Тбайт, где хранятся атрибуты вершин и ребер графа, буферизируются поступающие запросы на обработку и визуализацию графов, хранятся временные данные об изменениях в графах. В хост-подсистеме используется процессор с архитектурой x86 для обеспечения сетевого взаимодействия и связи системы с внешним миром. В функции хост-подсистемы входят:
-
на стадии инициализации комплекса: настройка сетевой подсистемы, подсистем хранения и обработки графов;
-
на стадии создания/изменения графов в локальной памяти подсистемы обработки графов: реализация очередей запросов на вставку/изменения, балансировка запросов к DISC системам, выделение и освобождение структур, контроль выполнения операций изменения;
-
на стадии запуска алгоритмов оптимизации: буферизация запросов оптимизации, инициализация процедур обработки, их запуск и контроль исполнения;
-
на стадии визуализации графов: буферизация запросов на визуализацию, настройка процедур формирования представлений графов для пользовательских процессов, запуск формирования представлений и контроль результатов, буферизация и передача представлений или изменений в представлениях пользовательским процессам.
Указанные функции реализованы в Программном ядре хост-подсистемы (host software kernel) – программном обеспечении, взаимодействующим с подсистемой обработки графов через шину PCIe.
2.2.2. Подсистема хранения графов
В подсистему хранения графов входят основная память 30Тбайт, состоящая из четырех NVMe SSD дисков по 7,7 Тбайт каждый. Технология NVMe (Non-Volatile Memory Express) обеспечивает интерфейс связи с увеличенной полосой пропускания, что повышает производительность и эффективность обработки графов.
2.2.3. Подсистема коммутации узлов
Подсистема коммутации узлов представляет собой два сетевых модуля связи по протоколу 100Gb Ethernet, позволяющих организовать соединение каждого гетерогенного узла с каждым другим узлом комплекса. Шина PCIe обеспечивает высокопроизводительное взаимодействие хост-подсистемы с процессорами Леонард Эйлер, а также последних с подсистемой хранения графов.
2.2.4. Подсистема обработки графов
Подсистема обработки графов каждого узла комплекса состоит из 3-х или 4-х карт (в зависимости от версии комплекса) многоядерных микропроцессоров Леонард Эйлер, каждый из которых в свою очередь включает 3 или 4 группы гетерогенных ядер (так называемых Core Groups, CG). В каждую такую группу входят от 2-х до 6-ти ядер DISC GPC, обладающих следующими характеристиками: объем доступной локальной памяти для хранения графов - до 2.5 Гбайт; разрядность ключей и значений - 64 бита; количество хранимых ключей и значений - до 117 миллионов; количество одновременно хранимых структур в локальной памяти структур - до 7; объем ОЗУ CPE - 64 КБайт. Взаимодействие гетерогенных DISC ядер и хост-подсистемы осуществляется как через FIFO буферы, так и через адресуемую Глобальную память (Global memory, GM) размером 128 Кбайт, что позволяет выбирать наиболее эффективный механизм взаимодействия.
Таким образом, комплекс «Тераграф» может содержать до 288 гетерогенных ядра DISC GPC, и хранить в оперативном доступе (в локальной памяти подсистемы обработки графов) до 11 миллиардов вершин. Группа ядер Core Group содержит контроллеры памяти, которые обеспечивает взаимодействие между GPC и Локальной памятью структур типа DDR4, а также с Глобальной памятью. Один и тот же блок Глобальной памяти используется всеми гетерогенными ядрами группы для передачи данных внутри группы и обмена данными с хост-подсистемой.
Структурная схема микропроцессора Леонард Эйлер версии 4 представлена на рисунке 5. В качестве единицы передаваемых данных принят блок размером 4КБ, который передается между хост-подсистемой и группой ядер CG с помощью механизмов прямого доступа к памяти.
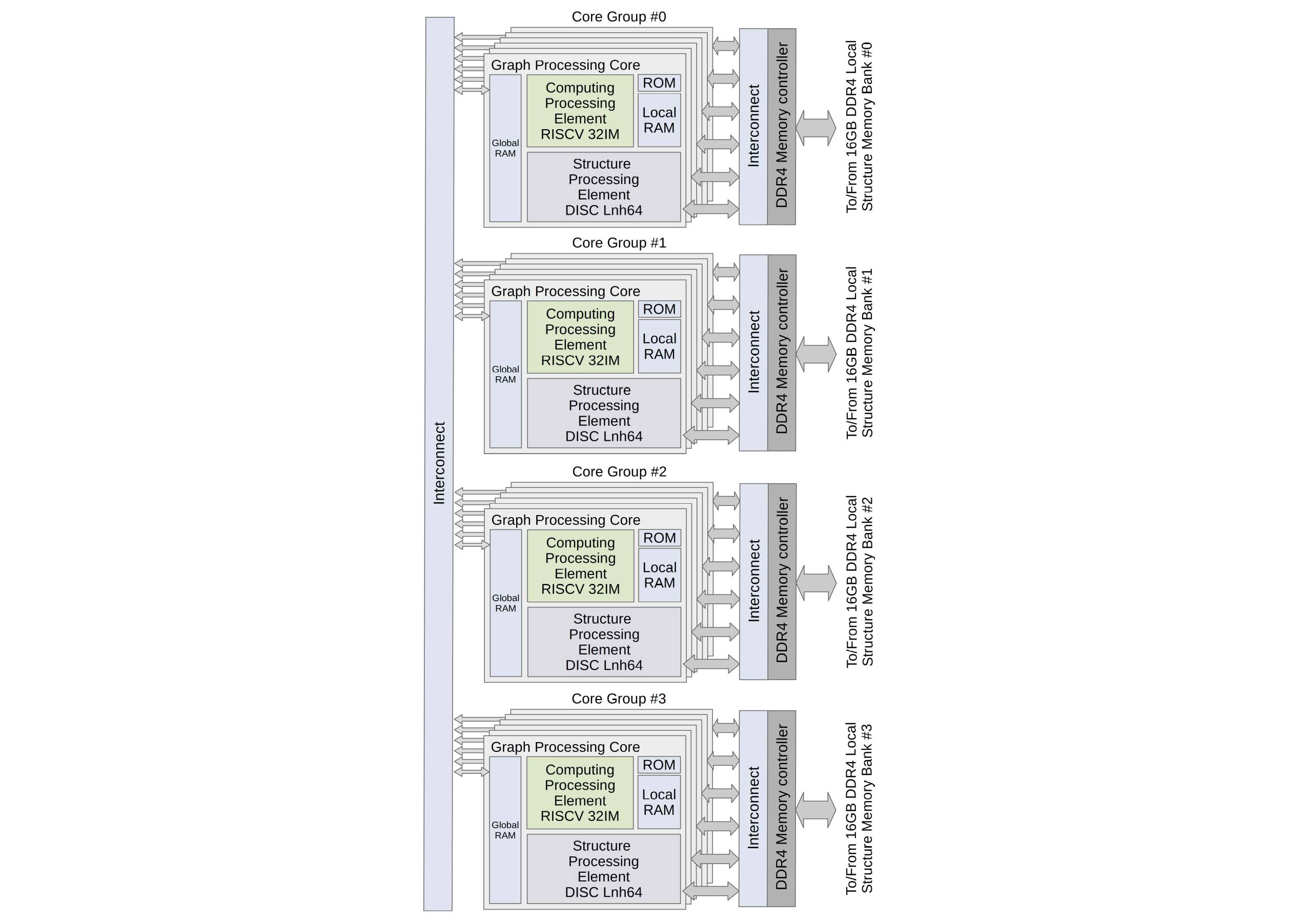 Рисунок 5 — Структура микропроцессора Леонард Эйлер
Рисунок 5 — Структура микропроцессора Леонард Эйлер
2.3. Микроархитектура гетерогенного ядра обработки графов
Как было отмечено ранее, обработка графов в системе Тераграф выполняется на многочисленных гетерогенных ядрах, состоящих из двух микропроцессоров: CPE и SPE (см. рисунок 6). При этом CPE является универсальным RISC ядром с арифметическим набором команд, в то время как SPE реализует набором команд дискретной математики. Каждый вычислительный элемент CPE состоит из очереди команд, блока выборки, блока декодирования команд, модуля предсказания переходов, арифметико-логического устройства, устройства доступа в память, интерфейса AXI4MM, блока ветвлений и интерфейса шины ускорителя AXL. Также вычислительный элемент связан шиной памяти с ПЗУ, в которой записан загрузчик, обеспечивающий передачу программных ядер. Для размещения программ и данных, каждый CPE имеет оперативную память размером 64КБ.
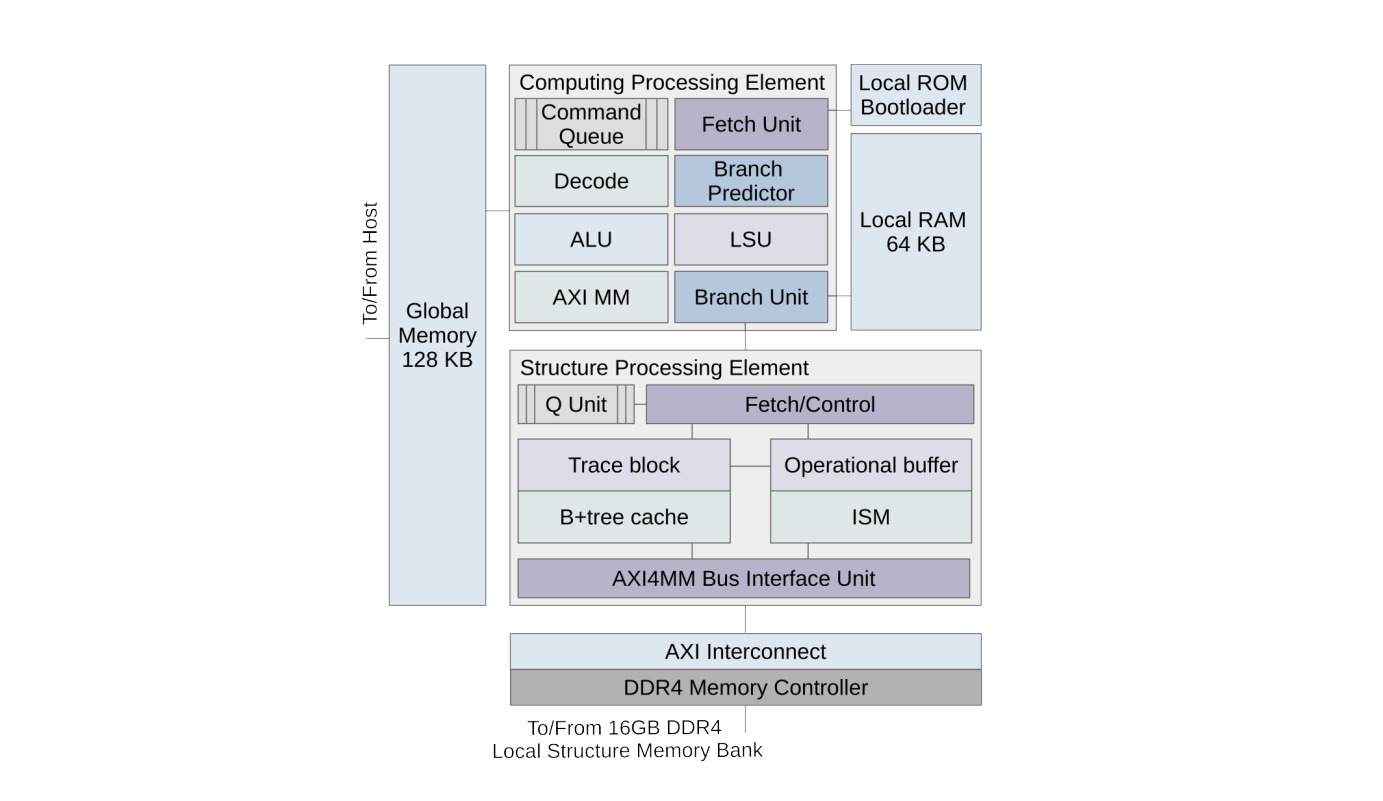 Рисунок 6 — Структура ядра обработки графов
Рисунок 6 — Структура ядра обработки графов
Под управлением поступающих из хост-подсистемы команд SPE выполняет хранение ключей и значений в многоуровневой подсистеме памяти, выполняет поиск, изменение и выдачу информации другим устройствам комплекса. Для ускорения поиска и обработки всего набора команд микропроцессор использует внутреннее представление множеств в виде B+деревьев, для которых возможна параллельная обработка нескольких вершин дерева как на промежуточных уровнях, используемых для поиска,так и на нижнем уровне, хранящем непосредственно ключи и значения.
2.4. Принципы взаимодействия микропроцессора Леонард Эйлер и хост-подсистемы
Основу взаимодействия подсистем при обработке графов составляет передача блоков данных и коротких сообщений между GPC и хост-подсистемой. Для передачи сообщений для каждого GPC реализованы два аппаратных FIFO буфера на 512 записей: Host2GPC для передачи от хост-подсистемы к ядру, и GPC2Host для передачи в обратную сторону.
Обработка начинается с того, что собранное программное ядро (software kernel) загружается в локальное ОЗУ одного или нескольких CPE (микропроцессора riscv32im). Для этого используется механизм прямого доступа к памяти со стороны хост-подсистемы. В свою очередь, GPC (один или несколько) получают сигнал о готовности образа software kernel в Глобальной памяти, после чего вызывается загрузчик, хранимый в ПЗУ CPE. Загрузчик выполняет копирование программного ядра из Глобальной памяти в ОЗУ CPE и передает управление на начальный адрес программы обработки. Предусмотрен режим работы GPC, при котором во время обработки происходит обмен данными и сообщениями. Эти два варианта работы реализуется через буферы и очереди соответственно. На рисунке 7 представлена диаграмма последовательностей первого сценария работы – вызов обработчика с передачей параметров и возвратом значения через очередь сообщений.
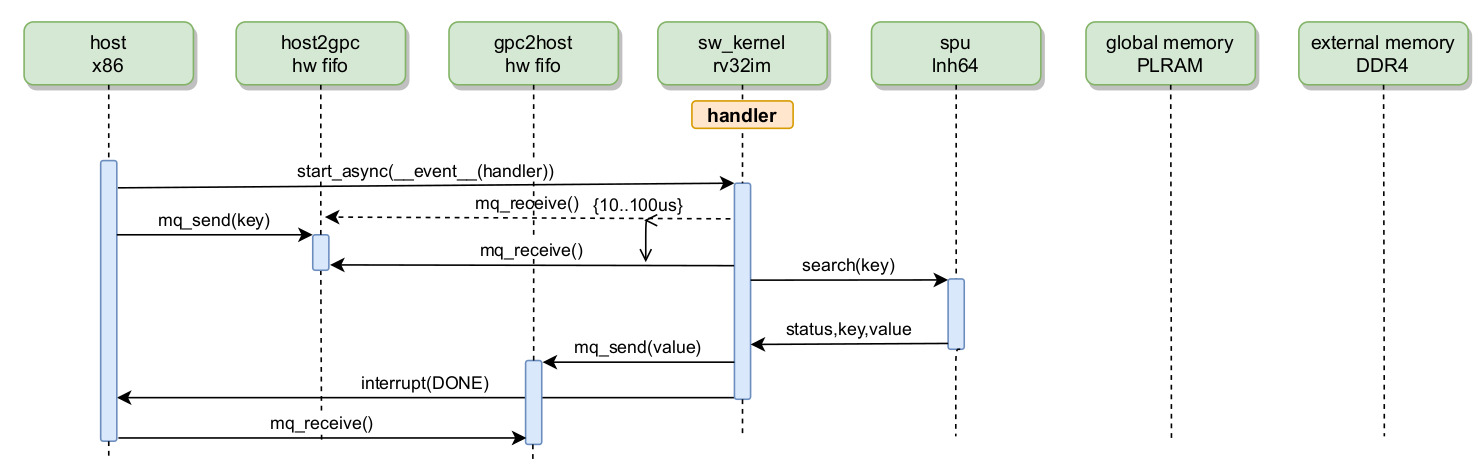 Рисунок 7 — Диаграмма последовательностей вызова обработчика с передачей параметров и возвратом значения через очередь сообщений
Рисунок 7 — Диаграмма последовательностей вызова обработчика с передачей параметров и возвратом значения через очередь сообщений
Если код программного ядра уже загружен в ОЗУ CPE, хост-подсистема может вызвать любой из содержащихся в нем обработчиков. Для этого в GPC передает оговоренный UID обработчика (handler), после чего передается сигнал запуска (сигнал START). В ответ CPE устанавливает состояние BUSY и начинает саму обработку. В ходе обработки ядро может обмениваться сообщениями с хост-подсистемой через очереди (команды mq_send и mq_receive). По завершении обработки устанавливается состояние IDLE и вырабатывается прерывание, которое перехватывается хост-подсистемой. Далее, пользовательское приложение хост-подсистемы уведомляется о завершении обработки и готовности результатов.
Если во время работы над кодом обработчика программному ядру software kernel требуется осуществить передачу больших блоков данным между CPE и хост-подсистемой, то может быть задействована Глобальная память и внешняя память большого размера (External Memory, до 16ГБ). Указанные варианты взаимодействия предполагает выделение и освобождение буферов и передачу указателей на них от хост-подсистемы к CPE. Соответствующая диаграмма последовательностей представлена на рисунке 8.
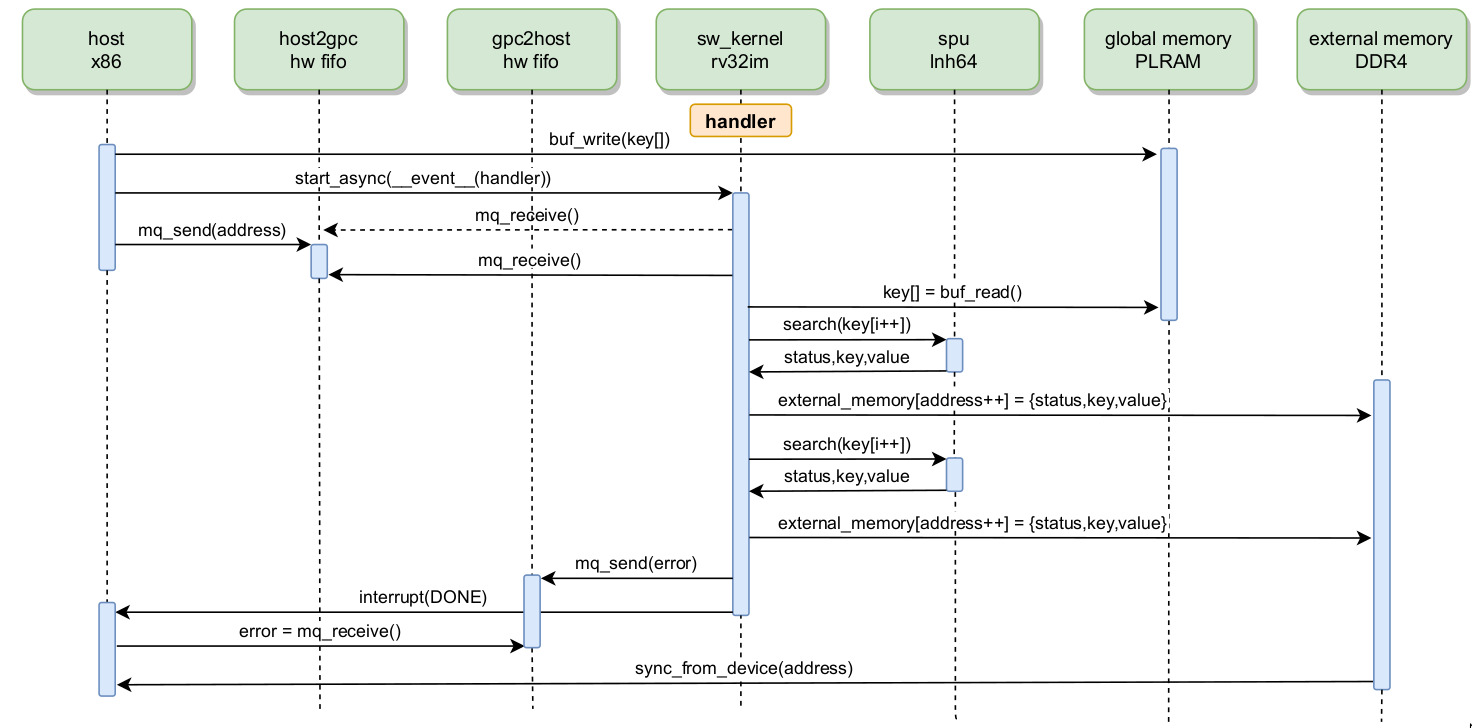 Рисунок 8 — Диаграмма последовательностей вызова обработчика с передачей параметров и возвратом значения через буфер в памяти сообщений
Рисунок 8 — Диаграмма последовательностей вызова обработчика с передачей параметров и возвратом значения через буфер в памяти сообщений
На приведенном примере хост-подсистема передает информацию (ключ поиска) через буфер в глобальную память. Далее, происходит процесс инициализации асинхронной работы путем отправки UID обработчика в GPC (handler UID). Далее хост-подсистема может продолжить передачу данных, получая подтверждения от процесса обработчика GPC через очередь сообщений. Как правило, обработчик, запущенный в CPE, активно вызывает DISC команды SPE, передает данные и получает результаты от SPE в хост-подсистему. В конце работы, обработчик передает результаты обратно в хост-подсистему с использованием очереди сообщений или Глобальной памяти.
2.5. Библиотека leonhard x64 xrt
Библиотека leonhard x64 xrt представляет собой API системного уровня, реализующего функциональные возможности по инициализации подсистемы обработки графов и взаимодействию с микропроцессором lnh64 DISC. Библиотека разделена на две части, представленные в таблице 2.
Таблица 2 - Описание частей библиотеки leonhard x64 xrt
| Раздел библиотеки | Описание | Язык программирования | Архитектура, Компилятор | Способ отладки |
|---|---|---|---|---|
| Host Lib | Управления хост-подсистемой и взаимодействие с ядрами GPC | C++, объектная модель | x86, g++ | gdb, Eclipse IDE |
| SW Kernel Lib | Взаимодействие с микропроцессором lnh64 | C, процедурная модель | riscv32, g++ | Вывод сообщений |
Функциональные возможности Host Lib:
-
Настройка параметов в зависимости от версии микропроцесора Леонард Эйлер.
-
Начальная инициализация аппаратной части, конфигурирование ПЛИС микропроцессором Леонард Эйлер.
-
Инициализация буферов и очередей для взаимодействия хост-подсистемы и подсистемы обработки графов (ядер обработки графов GPC).
-
Передача и прием данных и сообщений к/от GPC через общую память и аппаратные очереди.
Функциональные возможности SW Kernel Lib:
-
Обмен данными и сообщениями с хост-подсистемой.
-
Установка состояния sw_kernel (IDLE,BUSY).
-
Запуск обработчиков на ядре riscv32im.
-
Передача опрандов и кодов операций в микропроцессор lnh64.
-
Контроль результатов исполнения DISC команд.
Ниже приведен пример кода программы хост-подсистемы, выполняющей инициализацию и измерение тактовой частоты GPC.
//Общесистемные библиотеки
#include <iostream>
#include <stdio.h>
#include <stdexcept>
#include <iomanip>
#include <unistd.h>
#include <sys/time.h>
//Библиотеки Xilinx Runtime Library
#include "experimental/xrt_device.h"
#include "experimental/xrt_kernel.h"
#include "experimental/xrt_bo.h"
#include "experimental/xrt_ini.h"
//Библиотека leonhard x64 xrt
#include "gpc_defs.h"
#include "leonhardx64_xrt.h"
#include "gpc_handlers.h"
int main(int argc, char** argv)
{
// Приложение запскается с параметрами: <xclbin> <sw_kernel>
// <xclbin> - путь к бинарному файлу прошивки ПЛИС Ultrascale+ с проектом Леонард Эйлер
// <sw_kernel> - путь к бинарному файлу sw_kernel в формате rawbinary
unsigned int err = 0;
unsigned int cores_count = 0;
float LNH_CLOCKS_PER_SEC;
//Использование макроса __foreach_core для определения количества доступных ядер
__foreach_core(group, core) cores_count++;
//Проверка передаваемых параметров
if (argc < 3) {
usage();
throw std::runtime_error("FAILED_TEST\nNo xclbin or sw_kernel specified");
}
//Инициализация карты #0 и конфигурирование ускорителя
leonhardx64 lnh_inst = leonhardx64(0,argv[1]);
//Иницилиация программных ядер во всех GPC
__foreach_core(group, core)
{
lnh_inst.load_sw_kernel(argv[2], group, core);
}
/*
*
* Чтение номера версии и статуса из микропроцесосра lnh64 каждого GPC
*
*/
__foreach_core(group, core)
{
printf("Group #%d \tCore #%d\n", group, core);
// Запуск обработчика get_version() в sw_kernel
lnh_inst.gpc[group][core]->start_sync(__event__(get_version));
// Получение сообщения о номере версии (метод класса leonhardx64.mq_receive())
printf("\tSoftware Kernel Version:\t0x%08x\n", lnh_inst.gpc[group][core]->mq_receive());
// Запуск обработчика get_lnh_status_high() в sw_kernel
lnh_inst.gpc[group][core]->start_sync(__event__(get_lnh_status_high));
// Получение сообщения со значением старшей части регистра статуса
printf("\tLeonhard Status Register:\t0x%08x", lnh_inst.gpc[group][core]->mq_receive());
// Получение сообщения со значением младшей части регистра статуса
lnh_inst.gpc[group][core]->start_sync(__event__(get_lnh_status_low));
printf("_%08x\n", lnh_inst.gpc[group][core]->mq_receive());
}
/*
*
* Измерение тактовой частоты GPC[0]
*
*/
// Запуск обработчика frequency_measurement() в sw_kernel
lnh_inst.gpc[0][LNH_CORES_LOW[0]]->start_async(__event__(frequency_measurement));
// Команда обмена синхронизирующими сообщениями
lnh_inst.gpc[0][LNH_CORES_LOW[0]]->sync_with_gpc(); // Start measurement
// Задержка 1 секунда
sleep(1);
// Команда обмена синхронизирующими сообщениями
lnh_inst.gpc[0][LNH_CORES_LOW[0]]->sync_with_gpc(); // Start measurement
// Ожидание завершения работы обработчика
lnh_inst.gpc[0][LNH_CORES_LOW[0]]->finish();
// Чтение сообщения из очереди сообщений
LNH_CLOCKS_PER_SEC = (float)lnh_inst.gpc[0][LNH_CORES_LOW[0]]->mq_receive();
printf("Leonhard clock frequency (LNH_CF): %u MHz\n", LNH_CLOCKS_PER_SEC / 1000000);
exit(0);
}
Для представленного листинга должен быть также создан и скомпилирован ответный код для микропроцессора riscv32im, который будет работать в составе гетерогенного ядра обработки графов. В коде должна быть реализована логика установки состояния ядра: одно из двух состояний IDLE или BUSY. Также разработчиком должы быть реализованы обработчики вызываемых из хост-подсистемы функций get_version(), get_lnh_status_high(), get_lnh_status_low(), frequency_measurement().
Номер обработчика может быть задан явным обраом в Xост и sw_kernel частях, однако удобнее использовать механизм автоматической нумерации обработчиков на основе макросов С. Для этого мы будем использовать файл gpc_handkers.h, который должен быть включен как в проект хоста, так и в проект sw_kernel:
#ifndef DEF_HANDLERS_H_
#define DEF_HANDLERS_H_
#define DECLARE_EVENT_HANDLER(handler) \
const unsigned int event_ ## handler =__LINE__; \
void handler ();
#define __event__(handler) event_ ## handler
// Event handlers declarations by declaration line number!!!
DECLARE_EVENT_HANDLER(frequency_measurement);
DECLARE_EVENT_HANDLER(get_lnh_status_low);
DECLARE_EVENT_HANDLER(get_lnh_status_high);
DECLARE_EVENT_HANDLER(get_version);
#endif
Таким образом, условное имя обработчика ставится в однозначное соответствие номеру строки, в которой он объявлен в файле gpc_handlers.h.
В результате получим следующий код основного модуля sw_kernel
#include <stdlib.h>
#include "lnh64.h"
#include "gpc_io_swk.h"
#include "gpc_handlers.h"
#define VERSION 26
#define DEFINE_LNH_DRIVER
#define DEFINE_MQ_R2L
#define DEFINE_MQ_L2R
// Объявление структур для доступа к ресурсам микропроцессора lnh64
extern lnh lnh_core;
// Объявление структур для доступа к глобальной и внешней памяти, и очередям сообщений
extern global_memory_io gmio;
volatile unsigned int event_source;
int main(void) {
/////////////////////////////////////////////////////////
// Основной цикл запуска обработчиков
/////////////////////////////////////////////////////////
//Инициализация микропроцессорного ядра lnh64
lnh_init();
//Инициализация очередей host2gpc и gpc2host
gmio_init(lnh_core.partition.data_partition);
for (;;) {
//Ожидание события start
while (!gpc_start());
//Переход в режим BUSY и разрешение ввода/вывода
set_gpc_state(BUSY);
//Получение номера обработчика
event_source = gpc_config();
//Вызов обработчика по номеру
switch(event_source) {
case __event__(frequency_measurement) : frequency_measurement(); break;
case __event__(get_lnh_status_low) : get_lnh_status_low(); break;
case __event__(get_lnh_status_high) : get_lnh_status_high(); break;
case __event__(get_version): get_version(); break;
}
//Переход в режим IDLE и запрет ввода/вывода
set_gpc_state(IDLE);
while (gpc_start());
}
}
//-------------------------------------------------------------
// Глобальные переменные (для сокращения объема кода)
//-------------------------------------------------------------
u64 TSC_start;
u64 TSC_stop;
u32 interval;
//-------------------------------------------------------------
// Измерение тактовой частоты GPC
//-------------------------------------------------------------
void frequency_measurement() {
sync_with_host();
lnh_sw_reset();
lnh_rd_reg32_byref(TSC_LOW,&TSC_start);
sync_with_host();
lnh_rd_reg32_byref(TSC_LOW,&TSC_stop);
interval = TSC_stop-TSC_start;
mq_send(interval);
}
//-------------------------------------------------------------
// Получить версию микрокода
//-------------------------------------------------------------
void get_version() {
mq_send(VERSION);
}
//-------------------------------------------------------------
// Получить регистр статуса LOW Leonhard
//-------------------------------------------------------------
void get_lnh_status_low() {
lnh_rd_reg32_byref(LNH_STATE_LOW,&lnh_core.result.status);
mq_send(lnh_core.result.status);
}
//-------------------------------------------------------------
// Получить регистр статуса HIGH Leonhard
//-------------------------------------------------------------
void get_lnh_status_high() {
lnh_rd_reg32_byref(LNH_STATE_HIGH,&lnh_core.result.status);
mq_send(lnh_core.result.status);
}
2.5.1. Обмен данными между GPC и хост-подсистемой через глобальную память
Взаимодействие обработчика sw_kernel и хост-подсистемы может выполняться через Глобальную память размером 128 КБ, распределенную между ядрами одной группы (до 6 ядер, в зависимости от модификации) следующим образом:
Таблица 3 - Карта распределение глобальной памяти
| Начальный адрес | Размер | Назначение |
|---|---|---|
| 0 | 64K | Буфер для загрузки образов sw_kernel |
| 64K | 4K | Буфер Host2GPC для GPC0 |
| 68K | 4K | Буфер GPC2Host для GPC0 |
| 72K | 4K | Буфер Host2GPC для GPC1 |
| 76K | 4K | Буфер GPC2Host для GPC1 |
| … | … | … |
| 120K | 4K | Буфер Host2GPC для GPC5 |
| 124K | 4K | Буфер GPC2Host для GPC5 |
Распределение адресов в соответствии с картой Глобальной памяти выполняется хост-подсистемой при инициализации управляющего объекта leonhardx64 lnh_inst = leonhardx64(0,argv[1]);.
После инициализации обмен через Глобальную память может выполняться без какой-либо допонительной инициализации sw_kernel. Так как в основе обмена данными лежит механизм прямого доступа к памяти, необходимо подготовить буфер в пользовательском пространстве памяти хост-подсистемы
Пример кода хост-подсистемы для обмена данными через глобальную память:
//Выделение буфера в RAM хост-посистемы для передачи
unsigned int *host2gpc_buffer[LNH_GROUPS_COUNT][LNH_MAX_CORES_IN_GROUP];
__foreach_core(group, core)
host2gpc_buffer[group][core] = (unsigned int*) malloc(1024*sizeof(int));
//Запись данных в буферы Host2GPC
__foreach_core(group, core)
lnh_inst.gpc[group][core]->buf_write(1024*sizeof(int),(char*)host2gpc_buffer[group][core]);
//Передача сигнала о готовности буфера и его размера
__foreach_core(group, core) {
lnh_inst.gpc[group][core]->mq_send(1024*sizeof(int));
Пример ответного кода sw_kernel
unsigned int size = mq_receive();
unsigned int *buffer = (unsigned int*)malloc(size);
buf_read(size, buffer);
Аналогичным образом может быть организована обратная передача через буфер GPC2Host с помощью метода leonhardx64->buf_read (в хост-подсистеме) и buf_write (в sw_kernel).
Если необходимо передавать большие блоки данных, то указанную процедуру можно повторять несколько раз. Органичивающим фактором для повышения размеров буферов является не только незначительный размер Глобальной памяти, но и малый размер RAM CPE riscv32im (64 КБ).
2.5.2. Обмен данными между GPC и хост-подсистемой через внешнюю память
В текущей версии микропроцессора имеется возможность обмена через внешнюю память 16ГБ. Данный способ в дальнейшем использоваться не будет. В текущей версии он может быть использован в ограниченном режиме: размер передаваемого блока не может превосходить 512МБ. Для использования данного механизма требуется выделить буфер соответствующего размера в адресном пространстве хост-подсистемы и отобразить его на физическое адресное пространство ввода-вывода. Этот механизм реализован в библиотеке leonhard x64 xrt.
Пример кода хост-подсистемы для обмена данными через внешнюю память:
//Выделение буфера в RAM хост-посистемы для передачи
char* host2gpc_ext_buffer[LNH_GROUPS_COUNT][LNH_MAX_CORES_IN_GROUP];
__foreach_core(group, core)
host2gpc_ext_buffer[group][core] = lnh_inst.gpc[group][core]->external_memory_create_buffer(1024*1024*sizeof(int));
//Отображение буфера в пространство ввода-вывода и запись данных External memory
__foreach_core(group, core)
lnh_inst.gpc[group][core]->external_memory_sync_to_device(0,8192*sizeof(int));
//Передача физического адреса начала буфера
__foreach_core(group, core) {
long long tmp = lnh_inst.gpc[group][core]->external_memory_address();
lnh_inst.gpc[group][core]->mq_send((unsigned int)tmp);
}
//Передача сигнала о готовности буфера и его размера
__foreach_core(group, core) {
lnh_inst.gpc[group][core]->mq_send(1024*sizeof(int));
}
Пример ответного кода sw_kernel:
unsigned int buffer_pointer = mq_receive();
unsigned int size = mq_receive();
unsigned int *buffer = (unsigned int*)malloc(size);
ext_buf_read(size, (unsigned int *)buffer_pointer, buffer);
Обратите внимание, что в данном примере происходит копирование всего переданного буфера в RAM, так что размер передаваемых данных ограничен имеющимся свободным пространством оперативной памяти CPE (менее 64КБ).
2.6. Взаимодействие CPE(riscv32im) и SPE(lnh64)
Микропроцессор lnh64 с набором команд дискретной математики (Discrete Mathematics Instruction Set Computer) является ассоциативным процессором, т.е. устройством, выполняющим операции обработки над данными, хранящимися в ассоциативной памяти (так называемой Локальной памяти структур). В качестве таковой выступает адресная память DDR4, причем для каждого ядра lnh64 доступны 2.5 ГБ адресного пространства в ней. Для организации ассоциативного способа доступа к адресному устройству микропроцессор lnh64 организует на аппаратном уровне структуру B+дерева. Причем 512МБ занимает древовидая структура от верхнего и до предпоследнего уровня, 2048МБ занимает последний уровень дерева, на котором и хранятся 64х разрядные ключи и значения. Каждый микропроцессор lnh64 может хранить и обрабатывать до 117 миллионов ключей и значений.
Исходя из этого, обработка множеств или графов представляется в DISC наборе команд, как работа со структурами ключей и значений (key-value). Однако, как было показано ранее при описании набора команд DISC, в отличие от общепринятых key-value хранилищ, доступны такие операции как ближайший больший (NGR), ближайший меньший (NSM), команды объединения множеств (OR) и ряд других. Это и позволяет использовать lnh64 в качестве устройства, хранящего большие множества (для графов это множества вершин и ребер).
Доступ к микропроцессору lnh64 (Structure Processing Element) осуществляется чтением и записью в пространство памяти микропроцессора riscv32im (Computing Processing Element) в диапазоне 0x60000000 - 0x60001000. Карта памяти представлена в файле gpc_swk.h:
Таблица 4. Карта памяти CPE riscv32im
| Начальный адрес | Размер пространства (байт) | Назначение |
|---|---|---|
| 0x00000000 | 128 | ROM - содержит начальный загрузчик (bootloader) |
| 0x60000000 | 4K | lnh64 - просранство микропроцессора lnh64 с набором команд DISC |
| 0x80000000 | 64К | RAM - оперативная память микропроцессора riscv32im |
| 0xA0000000 | 128К | Глобальная память (global memory) |
| 0xA0020000 | 4 | Регистр статуса |
| 0xA0030000 | 4 | Регистр управления |
| 0xA0040000 | 4 | Очередь GPC2HOST |
| 0xA0050000 | 4 | Очередь HOST2GPC |
| 0xA0060000 | 4 | Регистр статуса очередей |
| 0xA0060008 | 4 | Регистр управления очередями |
| 0xA8000000 | 512М | Внешняя память (external memory) |
2.6.1. Программная модель микропроцессора lnh64
Микропроцессор lnh64 является 64-х разрядным, в то время как микропроцессор riscv32im является 32-х разрядным. В связи с этим для всех регистров lnh64 обеспечивается доступ как к младшей так и к старшей частям, используя 32-х разрядную шину памяти.
Микропроцессор lnh64 получает на вход команды 6 различных форматов. Так, для команды вставки INS задействуются регистр кода операции, регистр ключа операнда и регистр значения операнда. Результатом выполнения команды является статус ее исполнения, который записывается в регистр статуса. Для команды поиска SRCH задействуются регистры ключа операнда и регистр кода операции, а результаты записываются в регистры ключа результата, значения результата и регистр статуса.
Перечень программно-доступных регистров и их смещения в адресном пространстве относительно базового адреса (0x60000000) указан в таблице 5:
Таблица 5. Программно досупные регистры lnh64
| Регистр | Смещение | Режим | Начальное значение | Назначение |
|---|---|---|---|---|
| KEY2LNH_LOW | 0x0000 | запись | 0x00000000 | Регистр содержит младшую часть ключа операнда команд DISC |
| LNH2KEY_LOW | 0x0000 | чтение | 0x00000000 | Регистр содержит младшую часть ключа результата команды DISC |
| KEY2LNH_HIGH | 0x0004 | запись | 0x00000000 | Регистр содержит старшую часть ключа операнда команд DISC |
| LNH2KEY_HIGH | 0x0004 | чтение | 0x00000000 | Регистр содержит старшую часть ключа результата команды DISC |
| VAL2LNH_LOW | 0x0008 | запись | 0x00000000 | Регистр содержит младшую часть значения операнда команд DISC |
| LNH2VAL_LOW | 0x0008 | чтение | 0x00000000 | Регистр содержит младшую часть значения результата команд DISC |
| VAL2LNH_HIGH | 0x000С | запись | 0x00000000 | Регистр содержит старшую часть значения операнда команд DISC |
| LNH2VAL_HIGH | 0x000С | чтение | 0x00000000 | Регистр содержит старшую часть значения результата команд DISC |
| CMD2LNH_LOW | 0x0010 | запись | 0x00000000 | Регистр содержит младшую часть кода операции DISC |
| LNH_STATE_LOW | 0x0010 | чтение | 0x09110611 | Регистр содержит младшую часть статуса микропроцессора lnh64 |
| CMD2LNH_HIGH | 0x0014 | запись | 0x00000000 | Регистр содержит старшую часть кода операции DISC |
| LNH_STATE_HIGH | 0x0014 | чтение | 0x00000001 | Регистр содержит старшую часть статуса микропроцессора lnh64 |
| CARDINALITY_LOW | 0x0018 | чтение | 0x00000000 | Количество ключей в структуре (мл), указанной в поле R регистра CMD2LNH_LOW |
| CARDINALITY_HIGH | 0x001С | чтение | 0x00000000 | Количество ключей в структуре (ст), указанной в поле R регистра CMD2LNH_LOW |
| LNH_CNTL_LOW | 0x0020 | запись | 0x00000000 | Регистр управления (мл) |
| LNH_CNTL_HIGH | 0x0024 | запись | 0x00000000 | Регистр управления (ст) |
| LNH2KEYQ_LOW | 0x0028 | чтение | 0x00000000 | Очередь ключей результатов команд DISC (мл) |
| LNH2KEYQ_HIGH | 0x002С | чтение | 0x00000000 | Очередь ключей результатов команд DISC (ст) |
| LNH2VALQ_LOW | 0x0030 | чтение | 0x00000000 | Очередь значений результатов команд DISC (мл) |
| LNH2VALQ_HIGH | 0x0034 | чтение | 0x00000000 | Очередь значений результатов команд DISC (ст) |
| LNH_STATEQ_LOW | 0x0038 | чтение | 0x00000000 | Очередь статуса результатов команд DISC (мл) |
| LNH_STATEQ_HIGH | 0x003С | чтение | 0x00000000 | Очередь статуса результатов команд DISC (ст) |
| TSC_LOW | 0x0040 | чтение | 0x00000000 | Регистр счетчика тактов (мл) |
| TSC_HIGH | 0x0044 | чтение | 0x00000000 | Регистр счетчика тактов (ст) |
| СSC_LOW | 0x0048 | чтение | 0x00000000 | Регистр счетчика тактов исполнения команд (мл) |
| СSC_HIGH | 0x004C | чтение | 0x00000000 | Регистр счетчика тактов исполнения команд (ст) |
| DBG_A_LOW | 0x0050 | чтение | 0x00000000 | Регистр отладки A (мл) |
| DBG_A_HIGH | 0x0054 | чтение | 0x00000000 | Регистр отладки A (ст) |
| DBG_B_LOW | 0x0058 | чтение | 0x00000000 | Регистр отладки B (мл) |
| DBG_B_HIGH | 0x005С | чтение | 0x00000000 | Регистр отладки B (ст) |
| DBG_C_LOW | 0x0060 | чтение | 0x00000000 | Регистр отладки C (мл) |
| DBG_C_HIGH | 0x0064 | чтение | 0x00000000 | Регистр отладки C (ст) |
| DBG_D_LOW | 0x0068 | чтение | 0x00000000 | Регистр отладки D (мл) |
| DBG_D_HIGH | 0x006С | чтение | 0x00000000 | Регистр отладки D (ст) |
| MR0_LOW | 0x0080 | чтение | 0x00000000 | Регистр 0 mailbox с ожиданием результата (мл) |
| MR0_HIGH | 0x0084 | чтение | 0x00000000 | Регистр 0 mailbox с ожиданием результата (ст) |
| MR1_LOW | 0x0088 | чтение | 0x00000000 | Регистр 1 mailbox с ожиданием результата (мл) |
| MR1_HIGH | 0x008С | чтение | 0x00000000 | Регистр 1 mailbox с ожиданием результата (ст) |
| MR2_LOW | 0x0090 | чтение | 0x00000000 | Регистр 2 mailbox с ожиданием результата (мл) |
| MR2_HIGH | 0x0094 | чтение | 0x00000000 | Регистр 2 mailbox с ожиданием результата (ст) |
| MR3_LOW | 0x0098 | чтение | 0x00000000 | Регистр 3 mailbox с ожиданием результата (мл) |
| MR3_HIGH | 0x009С | чтение | 0x00000000 | Регистр 3 mailbox с ожиданием результата (ст) |
| MR4_LOW | 0x00A0 | чтение | 0x00000000 | Регистр 4 mailbox с ожиданием результата (мл) |
| MR4_HIGH | 0x00A4 | чтение | 0x00000000 | Регистр 4 mailbox с ожиданием результата (ст) |
| MR5_LOW | 0x00A8 | чтение | 0x00000000 | Регистр 5 mailbox с ожиданием результата (мл) |
| MR5_HIGH | 0x00AC | чтение | 0x00000000 | Регистр 5 mailbox с ожиданием результата (ст) |
| MR6_LOW | 0x00B0 | чтение | 0x00000000 | Регистр 6 mailbox с ожиданием результата (мл) |
| MR6_HIGH | 0x00B4 | чтение | 0x00000000 | Регистр 6 mailbox с ожиданием результата (ст) |
| MR7_LOW | 0x00B8 | чтение | 0x00000000 | Регистр 7 mailbox с ожиданием результата (мл) |
| MR7_HIGH | 0x00BC | чтение | 0x00000000 | Регистр 7 mailbox с ожиданием результата (ст) |
Регистр управления содержит биты для управления ресурсами lnh64. Биты 0..31 устанавливаются в необходимое состояние записью соответствующего значения в регистр LNH_CNTL_LOW. Биты 32..63 при записи логической 1 выдают одиночный импульс сброса ресурса, после чего автоматически устанавливаются в значение 0. Назначение бит для регистра управления представлено в таблице 6.
Таблица 6. Назначение разрядов регистра управления
| Название | Бит | Назначение |
|---|---|---|
| ALLOW_LNH_FLAG | 0 | Разрешение работы lnh64 |
| SUSPEND_Q_FLAG | 1 | Останов выдачи транзакций из очереди запросов на запись в lnh64 |
| LSM_DMA_FLAG | 2 | Разрешение прямого доступа к LSM |
| LCM_DMA_FLAG | 3 | Не используется |
| ENABLE_TSC_FLAG | 4 | Разрешение работы счетчика тактов |
| ENABLE_READY_INT | 5 | Не используется |
| RESET_MAILBOX[0] | 32 | Запуск импульса сброса регистра mailbox[0] |
| RESET_MAILBOX[1] | 33 | Запуск импульса сброса регистра mailbox[1] |
| RESET_MAILBOX[2] | 34 | Запуск импульса сброса регистра mailbox[2] |
| RESET_MAILBOX[3] | 35 | Запуск импульса сброса регистра mailbox[3] |
| RESET_MAILBOX[4] | 36 | Запуск импульса сброса регистра mailbox[4] |
| RESET_MAILBOX[5] | 37 | Запуск импульса сброса регистра mailbox[5] |
| RESET_MAILBOX[6] | 38 | Запуск импульса сброса регистра mailbox[6] |
| RESET_MAILBOX[7] | 39 | Запуск импульса сброса регистра mailbox[7] |
| RESET_SPU | 48 | Сброс lnh64 в начальное состояние (мягкий сброс) |
| RESET_ALL_QUEUES | 49 | Сброс состояния всех очередей |
| RESET_LNH2AXI_QUEUE | 50 | Сброс очереди запросов на чтение lnh64 |
| RESET_AXI2LNH_QUEUE | 51 | Сброс очереди запросов на запись lnh64 |
| RESET_TSC | 52 | Сброс счетчика тактов |
| RESET_RISCV | 53 | Аппаратный сброс lnh64 в начальное состояние |
Регистр статуса позволяет отслеживать готовность результатов выполнения операций (готовность, наличие ошибки), состояние очередей, версию аппаратного обеспечения и ряд других парамтеров. Назначение бит для регистра статуса представлено в таблице 7.
Таблица 7. Назначение разрядов регистра статуса
| Название | Бит | Назначение |
|---|---|---|
| SPU_READY_FLAG | 0 | Флаг завершения команды/готовности к приему команды |
| SPU_ERROR_FLAG | 1 | Флаг ошибки выполнения команды |
| SPU_ERROR_Q_FLAG | 2 | Флаг ошибки выполнения команды в очереди статуса результатов |
| DDR_Q_OVF_FLAG | 3 | Флаг переполнения очереди к DDR LSM памяти |
| DDR_TEST_SUCC_FLAG | 4 | Результат верификации контролера памяти DDR4 (не использован) = 0 |
| NU | 5-8 | Не использованы |
| SPU_ALL_DONE | 9 | Очередь команд пуста и последняя команда исполнена |
| AXI2LNH_Q_EMP_FLAG | 16 | Очередь запросов на запись пуста |
| AXI2LNH_Q_FULL_FLAG | 17 | Очередь запросов на запись переполнена |
| AXI2LNH_Q_AEMP_FLAG | 18 | Очередь запросов на запись наполовину пуста (содержит <256 значений) |
| AXI2LNH_Q_AFULL_FLAG | 19 | Очередь запросов на запись наполовину заполнена (содержит >256 значений) |
| LNH2AXI_Q_EMP_FLAG | 20 | Очередь запросов на чтение пуста |
| LNH2AXI_Q_FULL_FLAG | 21 | Очередь запросов на чтение переполнена |
| LNH2AXI_Q_AEMP_FLAG | 22 | Очередь запросов на чтение наполовину пуста (содержит <256 значений) |
| LNH2AXI_Q_AFULL_FLAG | 23 | Очередь запросов на чтение наполовину заполнена (содержит >256 значений) |
| MBOX_VFLAG | 32-40 | Биты готовности операндов в регистрах mailbox[0..7], 1 - готовность |
| LNH_DATA_PARTITION | 48-50 | Номер партиции DDR данных нижнего уровня B+дерева (0..7) |
| LNH_INDEX_PARTITION | 51-53 | Номер партиции DDR индексной части B+дерева (0..7) |
| LNH_INDEX_REGION | 54-55 | Номер региона DDR индексной части B+дерева в LNH_INDEX_PARTITION (0..3) |
2.6.2. Вызовы и передача операндов команд дискретной математики
Операции чтения и записи регистров lnh64 в DISC в библиотеке SW Kernel Lib выполняются с помощью макросов как при помощи непосредственных параметров (по значению), так и с помощью адреса параметра (по ссылке).
Таблица 8. Макросы доступа к регистрам lnh64
| Макрос | Назначение |
|---|---|
| lnh_wr_reg64_byref(adr, value) | Запись регистра 64 бит (Адрес, Данные) по ссылке |
| lnh_wr_reg64_byval(adr, value) | Запись регистра 64 бит (Адрес, Данные) по значению |
| lnh_rd_reg64_byref(adr, value) | Чтение регистра 64 бит (Адрес, Данные) по ссылке |
| lnh_rd_reg64_byval(adr) | Чтение регистра 64 бит (Адрес) => Данные по значению |
| lnh_wr_reg32_l2l_byref(adr, value) | Запись регистра 32 бит (Адрес, Данные) по ссылке |
| lnh_wr_reg32_byval(adr, value) | Запись регистра 32 бит (Адрес, Данные) по значению |
| lnh_rd_reg32_byref(adr, value) | Чтение регистра 32 бит (Адрес, Данные) по ссылке |
| lnh_rd_reg32_byval(adr) | Чтение регистра 32 бит (Адрес) => Данные по значению |
Для ускорения запуска команд, когда по сравнению с предыдущей командой меняется только часть операндов, может применяться функция __fast_recall(), передающая только измененные относительно предыдущей команды операнды и код операции.
Типичным примером использования макросов для запуска команды на выполнение и ожидание результатов является команда Вставки (INS) ключа и значения. Для этого, необходимо проверить возможность записи в очередь запросов на запись. При этом, обращение к очереди требуется выполнять только в том случае, если исчерпан лимит на количество последовательных операций записи (256 записей). Только в случае превышения лимита проверяется флаг AXI2LNH_Q_AFULL_FLAG. При освобождении половины от имеющего ся места в очереди посылка транзакций возобновлется.
Микроархитектура lnh64 допускает обращение к одной из семи независимых структур (1..7). Структура с инексом 0 не используется для хранения и зарезервирована.
Далее происходит запись ключей и значений в регистры KEY2LNH и VAL2LNH, а также посылка кода операции в регистр CMD2LNH. При этом указывается парамтер str, определяющий номер структуры, в которую должна произойти вставка нового ключа. После записи старшей части регистра CMD2LNH (CMD2LNH_HIGH) происходит запуск команды на исполнение.
Далее выполняется ожидание готовности (проверяется бит SPU_READY_FLAG регистра статуса), после чего выполняется чтение регистра состояния и анализ результата. Статус выполнения команды, а для других команд ключ и значение результата записываются в структуру lnh_core.result.
//====================================================
// Добавление (Структура, Ключ, Значение)
//====================================================
bool lnh_ins_sync(uint64_t str, uint64_t key, uint64_t value)
{
//проверка готовности устройства
lnh_axi2lnh_queue_credits_check;
//запись исходных данных
lnh_wr_reg64_byref(KEY2LNH, &key);
lnh_wr_reg64_byref(VAL2LNH, &value);
lnh_wr_reg64_byval(CMD2LNH, (INS<<lnh_cmd)|str);
//ожидание готовности очереди команд
lnh_sync();
//чтение результата
lnh_rd_reg64_byref(LNH_STATE,&lnh_core.result.status);
//results
if ((lnh_core.result.status & (1<<SPU_ERROR_FLAG)) != 0) {
return false;
} else {
return true;
}
}
Функции для вызова команд DISC организованы в виде шести групп:
Таблица 9. Функции библиотеки leonhard-x64-xrt-v2 для вызова команд DISC lnh64
| Группа функций / функция | Пояснение |
|---|---|
| Функции для работы с Leonhard API | В группу входят функции чтения и записи регистров Lnh64 |
| lnh_hw_reset() | Аппаратный сброс GPC, удаление всех структур Lnh64, сброс riscv микропроцессора, сброс очередей mq |
| lnh_sw_reset() | Программное удаление всех структур Lnh64 |
| lnh_init() | Инициализация lnh64, установка указателей на буферы Глобальной памяти |
| lnh_rd_reg64(adr) | Чтение 64 разрядного регистра lnh64 микропроцессора |
| lnh_rd_reg32(adr) | Чтение 32 разрядной части регистра lnh64 микропроцессора |
| lnh_fast_recall(key) lnh_fast_recall(key,value) |
Быстрый перезапуск предыдущей команды. Ускорение достигается благодаря передаче только части операндов (только ключ, только младшая часть ключа и т.д.) |
| Сервисные функции Leonhard API | В группу входят функции преобразования типов и ожидания готовности lnh64 |
| float2uint(value) | Представление значения типа float в целочисленном виде (инферсия знака мантиссы) для сохранения в ввиде поля ключа. Команда позволяет исопльзовать целочиссленное безщнаковое сравнение для чисел float |
| uint2float(value) | Функция, обратная к float2uint, позволяет преобразовать часть ключа, сохраненного в виде unsigned int в тип float |
| double2ull(value) | Представление значения типа double в целочисленном виде (инферсия знака мантиссы) для сохранения в ввиде поля ключа. Команда позволяет исопльзовать целочиссленное безщнаковое сравнение для чисел double |
| ull2double(value) | Функция, обратная к double2ull, позволяет преобразовать часть ключа, сохраненного в виде unsigned int в тип double |
| lnh_sync() | Ожидание готовности результатов выполнения команды в Lnh64. Функция ожидает завершения всех команд очереди команд Lnh64 |
| lnh_syncm(mbr) | Ожижание готовности регистра Mailbox. При запуске команд DISC с записью результатов в регистры mbr сбрасывется флаг достоверности указанных регистров. При помещении результатов в mbrx регистр, флаг устанавливается и разрешается его чтение. |
| Синхронные функции Leonhard API | Функции для вызова команд DISC с ожиданием их завершения и чтением результатов в структуру lnh_core.results |
| lnh_ins_sync(str,key,value) | Вставка ключа key и значения value в структуру str. |
| lnh_del_sync(str,key) | Удаление записи с ключом key из структуры str. |
| lnh_get_num(str) | Получить количество записей в структуре str. |
| lnh_del_str_sync(str) | Удаление структуры str. |
| lnh_sq_sync(str) | Сжатие структуры в памяти lnh64 (сокращение занимаемого объема памяти). |
| lnh_or_sync(A,B,R) | Объединение множеств ключей структуры A и B. Помещение результирующей структуры в R. |
| lnh_and_sync(A,B,R) | Пересечение множеств ключей структуры A и B. Помещение результирующей структуры в R. |
| lnh_not_sync(A,B,R) | Дополнение множеств ключей структуры A ключами структуры B. Помещение результирующей структуры в R. |
| lnh_lseq_sync(key,A,R) | Срез структуры A по условию “меньше или равно” ключа key. Помещение результирующей структуры в R (все ключи, не соответствующие условию lseq в структуре R отсуствуют). |
| lnh_ls_sync(key,A,R) | Срез структуры A по условию “меньше” ключа key. Помещение результирующей структуры в R. (все ключи, не соответствующие условию ls в структуре R отсуствуют). |
| lnh_greq_sync(key,A,R) | Срез структуры A по условию “больше или равно” ключа key. Помещение результирующей структуры в R.(все ключи, не соответствующие условию greq в структуре R отсуствуют). |
| lnh_gr_sync(key,A,R) | Срез структуры A по условию “больше” ключа key. Помещение результирующей структуры в R. (все ключи, не соответствующие условию gr в структуре R отсуствуют). |
| lnh_grls_sync(key_ls,key_gr,A,R) | Срез структуры A по условию “больше” ключа key_ls и “меньше” ключа key_gr. Помещение результирующей структуры в R. (все ключи, не соответствующие условию gr и ls в структуре R отсуствуют). |
| lnh_search(str,key) | Поиск ключа key в структуре str и выдача найденного ключа и значения value. |
| lnh_next(str,key) | Поиск следующего ключа, следующего за ключом key в структуре str. Поиск выполняется в целочисленном беззнаковом порядке на ключах. |
| lnh_prev(str,key) | Поиск предыдущего ключа, следующего перед ключом key в структуре str. Поиск выполняется в целочисленном беззнаковом порядке на ключах. |
| lnh_ngr(str,key) | Поиск следующего ключа, большего значению key в структуре str (ключ key может отсутствовать в структуре). Поиск выполняется в целочисленном беззнаковом порядке на ключах. |
| lnh_nsm(str,key) | Поиск следующего ключа, меньшего значению key в структуре str (ключ key может отсутствовать в структуре). Поиск выполняется в целочисленном беззнаковом порядке на ключах. |
| lnh_ngr_signed(str,key) | Поиск следующего ключа, большего значению key в структуре str (ключ key может отсутствовать в структуре). Поиск выполняется в целочисленном знаковом порядке на ключах. |
| lnh_nsm_signed(str,key) | Поиск следующего ключа, меньшего значению key в структуре str (ключ key может отсутствовать в структуре). Поиск выполняется в целочисленном знаковом порядке на ключах. |
| lnh_get_first(str) | Поиск наименьшего ключа структуры str. Поиск выполняется в целочисленном беззнаковом порядке на ключах. |
| lnh_get_last(str) | Поиск наибольшего ключа структуры str. Поиск выполняется в целочисленном беззнаковом порядке на ключах. |
| lnh_get_first_signed(str) | Поиск наименьшего ключа структуры str. Поиск выполняется в целочисленном знаковом порядке на ключах. |
| lnh_get_last_signed(str) | Поиск наибольшего ключа структуры str. Поиск выполняется в целочисленном знаковом порядке на ключах. |
| Синхронные функции Leonhard API с записью в очередь результатов | Функции для вызова команд DISC с ожиданием их завершения и автоматической записью результатов в очередь (регистры LNH2KEYQ, LNH2VALQ, LNH_STATEQ) |
| lnh_ins_syncq(str,key,value) | Вставка ключа key и значения value в структуру str. Запись результата в очередь. |
| lnh_del_syncq(str,key) | Удаление записи с ключом key из структуры str. Запись результата в очередь. |
| lnh_get_numq(str) | Получить количество записей в структуре str.Запись результата в очередь. |
| lnh_del_str_syncq(str) | Удаление структуры str. Запись результата в очередь. |
| lnh_sq_syncq(str) | Сжатие структуры в памяти lnh64 (сокращение занимаемого объема памяти). Запись результата в очередь. |
| lnh_or_syncq(A,B,R) | Объединение множеств ключей структуры A и B. Помещение результирующей структуры в R. Запись результата в очередь. |
| lnh_and_syncq(A,B,R) | Пересечение множеств ключей структуры A и B. Помещение результирующей структуры в R. Запись результата в очередь. |
| lnh_not_syncq(A,B,R) | Дополнение множеств ключей структуры A ключами структуры B. Помещение результирующей структуры в R. Запись результата в очередь. |
| lnh_lseq_syncq(key,A,R) | Срез структуры A по условию “меньше или равно” ключа key. Помещение результирующей структуры в R (все ключи, не соответствующие условию lseq в структуре R отсуствуют). Запись результата в очередь. |
| lnh_ls_syncq(key,A,R) | Срез структуры A по условию “меньше” ключа key. Помещение результирующей структуры в R. (все ключи, не соответствующие условию ls в структуре R отсуствуют). Запись результата в очередь. |
| lnh_greq_syncq(key,A,R) | Срез структуры A по условию “больше или равно” ключа key. Помещение результирующей структуры в R.(все ключи, не соответствующие условию greq в структуре R отсуствуют). Запись результата в очередь. |
| lnh_gr_syncq(key,A,R) | Срез структуры A по условию “больше” ключа key. Помещение результирующей структуры в R. (все ключи, не соответствующие условию gr в структуре R отсуствуют). Запись результата в очередь. |
| lnh_grls_syncq(key_ls,key_gr,A,R) | Срез структуры A по условию “больше” ключа key_ls и “меньше” ключа key_gr. Помещение результирующей структуры в R. (все ключи, не соответствующие условию gr и ls в структуре R отсуствуют). Запись результата в очередь. |
| lnh_searchq(str,key) | Поиск ключа key в структуре str и выдача найденного ключа и значения value. Запись результата в очередь. |
| lnh_nextq(str,key) | Поиск следующего ключа, следующего за ключом key в структуре str. Поиск выполняется в целочисленном беззнаковом порядке на ключах. Запись результата в очередь. |
| lnh_prevq(str,key) | Поиск предыдущего ключа, следующего перед ключом key в структуре str. Поиск выполняется в целочисленном беззнаковом порядке на ключах. Запись результата в очередь. |
| lnh_ngrq(str,key) | Поиск следующего ключа, большего значению key в структуре str (ключ key может отсутствовать в структуре). Поиск выполняется в целочисленном беззнаковом порядке на ключах. Запись результата в очередь. |
| lnh_nsmq(str,key) | Поиск следующего ключа, меньшего значению key в структуре str (ключ key может отсутствовать в структуре). Поиск выполняется в целочисленном беззнаковом порядке на ключах. Запись результата в очередь. |
| lnh_get_firstq(str) | Поиск наименьшего ключа структуры str. Поиск выполняется в целочисленном беззнаковом порядке на ключах. Запись результата в очередь. |
| lnh_get_lastq(str) | Поиск наибольшего ключа структуры str. Поиск выполняется в целочисленном беззнаковом порядке на ключах. Запись результата в очередь. |
| lnh_get_q() | Чтение результата из очереди |
| Асинхронные функции Leonhard API с записью в асинхронный Mailbox | Вызов команд DISC без ожидания их завершения и с записью результатов в регистры mbr. На стороне sw_kernel возможно чтение с ожиданием готовности mbr регистров функцией lnh_syncm(int mbr) |
| lnh_ins_syncm(st_mreg,str,key,value) | Вставка ключа key и значения value в структуру str. Запись результата в регистр st_mreg. |
| lnh_del_syncm(st_mreg,str,key) | Удаление записи с ключом key из структуры str. Запись результата в регистр st_mreg. |
| lnh_get_numm(str) | Получить количество записей в структуре str. Запись результата в регистр mrf. |
| lnh_del_str_syncm(st_mreg,str) | Удаление структуры str. Запись результата в регистр st_mreg. |
| lnh_sq_syncm(st_mreg,str) | Сжатие структуры в памяти lnh64 (сокращение занимаемого объема памяти). Запись результата в регистр st_mreg. |
| lnh_or_syncm(st_mreg,A,B,R) | Объединение множеств ключей структуры A и B. Помещение результирующей структуры в R. Запись результата в регистр st_mreg. |
| lnh_and_syncm(st_mreg,A,B,R) | Пересечение множеств ключей структуры A и B. Помещение результирующей структуры в R. Запись результата в регистр st_mreg. |
| lnh_not_syncm(st_mreg,A,B,R) | Дополнение множеств ключей структуры A ключами структуры B. Помещение результирующей структуры в R. Запись результата в регистр st_mreg. |
| lnh_lseq_syncm(st_mreg,key,A,R) | Срез структуры A по условию “меньше или равно” ключа key. Помещение результирующей структуры в R (все ключи, не соответствующие условию lseq в структуре R отсуствуют). Запись результата в регистр st_mreg. |
| lnh_ls_syncm(st_mreg,key,A,R) | Срез структуры A по условию “меньше” ключа key. Помещение результирующей структуры в R. (все ключи, не соответствующие условию ls в структуре R отсуствуют). Запись результата в регистр st_mreg. |
| lnh_greq_syncm(st_mreg,key,A,R) | Срез структуры A по условию “больше или равно” ключа key. Помещение результирующей структуры в R.(все ключи, не соответствующие условию greq в структуре R отсуствуют). Запись результата в регистр st_mreg. |
| lnh_gr_syncm(st_mreg,key,A,R) | Срез структуры A по условию “больше” ключа key. Помещение результирующей структуры в R. (все ключи, не соответствующие условию gr в структуре R отсуствуют). Запись результата в регистр st_mreg. |
| lnh_grls_syncm(st_mreg,key_ls,key_gr,A,R) | Срез структуры A по условию “меньше” ключfа key_ls и “больше” ключа key_gr. Помещение результирующей структуры в R. (все ключи, не соответствующие условию gr и ls в структуре R отсуствуют). Запись результата в регистр st_mreg. |
| lnh_searchm(key_mreg,val_mreg,st_mreg,str,key) | Поиск ключа key в структуре str и выдача найденного ключа и значения value. Запись результата в регистр st_mreg. |
| lnh_nextm(key_mreg,val_mreg,st_mregstr,key) | Поиск следующего ключа, следующего за ключом key в структуре str. Поиск выполняется в целочисленном беззнаковом порядке на ключах. Запись результата в регистр st_mreg. |
| lnh_prevm(key_mreg,val_mreg,st_mregstr,key) | Поиск предыдущего ключа, следующего перед ключом key в структуре str. Поиск выполняется в целочисленном беззнаковом порядке на ключах. Запись результата в регистр st_mreg. |
| lnh_ngrm(key_mreg,val_mreg,st_mregstr,key) | Поиск следующего ключа, большего значению key в структуре str (ключ key может отсутствовать в структуре). Поиск выполняется в целочисленном беззнаковом порядке на ключах. Запись результата в регистр st_mreg. |
| lnh_nsmm(key_mreg,val_mreg,st_mregstr,key) | Поиск следующего ключа, меньшего значению key в структуре str (ключ key может отсутствовать в структуре). Поиск выполняется в целочисленном беззнаковом порядке на ключах. Запись результата в регистр st_mreg. |
| lnh_get_firstm(key_mreg,val_mreg,st_mregstr) | Поиск следующего ключа, большего значению key в структуре str (ключ key может отсутствовать в структуре). Поиск выполняется в целочисленном знаковом порядке на ключах. Запись результата в регистр st_mreg. |
| lnh_get_lastm(key_mreg,val_mreg,st_mregstr) | Поиск следующего ключа, меньшего значению key в структуре str (ключ key может отсутствовать в структуре). Поиск выполняется в целочисленном знаковом порядке на ключах. Запись результата в регистр st_mreg. |
| lnh_get_m(mreg) | Чтение регистра Mailbox Запись результата в регистр st_mreg. |
| Асинхронные функции Leonhard API без записи результатов | Функции для вызова команд DISC без ожидания их завершения. Записью результатов выполнения команд не производится |
| lnh_ins_async(str,key,value) | Вставка ключа key и значения value в структуру str. |
| lnh_del_async(str,key) | Удаление записи с ключом key из структуры str. |
| lnh_del_str_async(str) | Удаление структуры str. |
| lnh_sq_async(str) | Сжатие структуры в памяти lnh64 (сокращение занимаемого объема памяти). |
| lnh_or_async(A,B,R) | Объединение множеств ключей структуры A и B. Помещение результирующей структуры в R. |
| lnh_and_async(A,B,R) | Пересечение множеств ключей структуры A и B. Помещение результирующей структуры в R. |
| lnh_not_async(A,B,R) | Дополнение множеств ключей структуры A ключами структуры B. Помещение результирующей структуры в R. |
| lnh_lseq_async(key,A,R) | Срез структуры A по условию “меньше или равно” ключа key. Помещение результирующей структуры в R (все ключи, не соответствующие условию lseq в структуре R отсуствуют). |
| lnh_ls_async(key,A,R) | Срез структуры A по условию “меньше” ключа key. Помещение результирующей структуры в R. (все ключи, не соответствующие условию ls в структуре R отсуствуют). |
| lnh_greq_async(key,A,R) | Срез структуры A по условию “больше или равно” ключа key. Помещение результирующей структуры в R.(все ключи, не соответствующие условию greq в структуре R отсуствуют). |
| lnh_gr_async(key,A,R) | Срез структуры A по условию “больше” ключа key. Помещение результирующей структуры в R. (все ключи, не соответствующие условию gr в структуре R отсуствуют). |
| lnh_grls_async(key_ls,key_gr,A,R) | Срез структуры A по условию “больше” ключа key_ls и “меньше” ключа key_gr. Помещение результирующей структуры в R. (все ключи, не соответствующие условию gr и ls в структуре R отсуствуют). |
Полный перечень функций вызовов команд DISC вы можете посмотреть в файле lnh64.h.
//==================================
// Функции для работы с Leonhard API
//==================================
void lnh_hw_reset();
void lnh_sw_reset();
void lnh_init();
uint64_t lnh_rd_reg64(int adr);
uint32_t lnh_rd_reg32(int adr);
void lnh_fast_recall(uint32_t key);
void lnh_fast_recall(uint32_t key, uint32_t value);
void lnh_fast_recall(uint64_t key);
void lnh_fast_recall(uint64_t key, uint64_t value);
//================================
// Сервисные функции Leonhard API
//================================
uint32_t float2uint(float value);
float uint2float(uint32_t value);
uint64_t double2ull(double value);
double ull2double(uint64_t value);
void lnh_sync();
void lnh_syncm(int mbr);
//================================
// Синхронные функции Leonhard API
//================================
bool lnh_ins_sync(uint64_t str, uint64_t key, uint64_t value);
bool lnh_del_sync(uint64_t str, uint64_t key);
uint32_t lnh_get_num(uint64_t str);
bool lnh_del_str_sync(uint64_t str);
bool lnh_sq_sync(uint64_t str);
bool lnh_or_sync(uint64_t A, uint64_t B, uint64_t R);
bool lnh_and_sync(uint64_t A, uint64_t B, uint64_t R);
bool lnh_not_sync(uint64_t A, uint64_t B, uint64_t R);
bool lnh_lseq_sync(uint64_t key, uint64_t A, uint64_t R);
bool lnh_ls_sync(uint64_t key, uint64_t A, uint64_t R);
bool lnh_greq_sync(uint64_t key, uint64_t A, uint64_t R);
bool lnh_gr_sync(uint64_t key, uint64_t A, uint64_t R);
bool lnh_grls_sync(uint64_t key_ls, uint64_t key_gr, uint64_t A, uint64_t R);
bool lnh_search(uint64_t str, uint64_t key);
bool lnh_next(uint64_t str, uint64_t key);
bool lnh_prev(uint64_t str, uint64_t key);
bool lnh_nsm(uint64_t str, uint64_t key);
bool lnh_ngr(uint64_t str, uint64_t key);
bool lnh_nsm_signed(uint64_t str, long long int key);
bool lnh_ngr_signed(uint64_t str, long long int key);
bool lnh_get_first(uint64_t str);
bool lnh_get_last(uint64_t str);
bool lnh_get_first_signed(uint64_t str);
bool lnh_get_last_signed(uint64_t str);
//================================================================
// Синхронные функции Leonhard API с записью в очередь результатов
//================================================================
bool lnh_ins_syncq(uint64_t str, uint64_t key, uint64_t value);
bool lnh_del_syncq(uint64_t str, uint64_t key);
uint32_t lnh_get_numq(uint64_t str);
bool lnh_del_str_syncq(uint64_t str);
bool lnh_sq_syncq(uint64_t str);
bool lnh_or_syncq(uint64_t A, uint64_t B, uint64_t R);
bool lnh_and_syncq(uint64_t A, uint64_t B, uint64_t R);
bool lnh_not_syncq(uint64_t A, uint64_t B, uint64_t R);
bool lnh_lseq_syncq(uint64_t key, uint64_t A, uint64_t R);
bool lnh_ls_syncq(uint64_t key, uint64_t A, uint64_t R);
bool lnh_greq_syncq(uint64_t key, uint64_t A, uint64_t R);
bool lnh_gr_syncq(uint64_t key, uint64_t A, uint64_t R);
bool lnh_grls_syncq(uint64_t key_ls, uint64_t key_gr, uint64_t A, uint64_t R);
bool lnh_searchq(uint64_t str, uint64_t key);
bool lnh_nextq(uint64_t str, uint64_t key);
bool lnh_prevq(uint64_t str, uint64_t key);
bool lnh_nsmq(uint64_t str, uint64_t key);
bool lnh_ngrq(uint64_t str, uint64_t key);
bool lnh_get_firstq(uint64_t str);
bool lnh_get_lastq(uint64_t str);
bool lnh_get_q();
//=================================================================
// Асинхронные функции Leonhard API с записью в асинхронный Mailbox
//=================================================================
bool lnh_ins_syncm(int st_mreg, uint64_t str, uint64_t key, uint64_t value);
bool lnh_del_syncm(int st_mreg, uint64_t str, uint64_t key);
uint32_t lnh_get_numm(uint64_t str);
bool lnh_del_str_syncm(int st_mreg, uint64_t str);
bool lnh_sq_syncm(int st_mreg, uint64_t str);
bool lnh_or_syncm(int st_mreg, uint64_t A, uint64_t B, uint64_t R);
bool lnh_and_syncm(int st_mreg, uint64_t A, uint64_t B, uint64_t R);
bool lnh_not_syncm(int st_mreg, uint64_t A, uint64_t B, uint64_t R);
bool lnh_lseq_syncm(int st_mreg, uint64_t key, uint64_t A, uint64_t R);
bool lnh_ls_syncm(int st_mreg, uint64_t key, uint64_t A, uint64_t R);
bool lnh_greq_syncm(int st_mreg, uint64_t key, uint64_t A, uint64_t R);
bool lnh_gr_syncm(int st_mreg, uint64_t key, uint64_t A, uint64_t R);
bool lnh_grls_syncm(int st_mreg, uint64_t key_ls, uint64_t key_gr, uint64_t A, uint64_t R);
bool lnh_searchm(int key_mreg, int val_mreg, int st_mreg, uint64_t str, uint64_t key);
bool lnh_nextm(int key_mreg, int val_mreg, int st_mreg, uint64_t str, uint64_t key);
bool lnh_prevm(int key_mreg, int val_mreg, int st_mreg, uint64_t str, uint64_t key);
bool lnh_nsmm(int key_mreg, int val_mreg, int st_mreg, uint64_t str, uint64_t key);
bool lnh_ngrm(int key_mreg, int val_mreg, int st_mreg, uint64_t str, uint64_t key);
bool lnh_get_firstm(int key_mreg, int val_mreg, int st_mreg, uint64_t str);
bool lnh_get_lastm(int key_mreg, int val_mreg, int st_mreg, uint64_t str);
uint64_t lnh_get_m(int mreg);
//========================================================
// Асинхронные функции Leonhard API без записи результатов
//========================================================
bool lnh_ins_async(uint64_t str, uint64_t key, uint64_t value);
bool lnh_del_async(uint64_t str, uint64_t key);
bool lnh_del_str_async(uint64_t str);
bool lnh_sq_async(uint64_t str);
bool lnh_or_async(uint64_t A, uint64_t B, uint64_t R);
bool lnh_and_async(uint64_t A, uint64_t B, uint64_t R);
bool lnh_not_async(uint64_t A, uint64_t B, uint64_t R);
bool lnh_lseq_async(uint64_t key, uint64_t A, uint64_t R);
bool lnh_ls_async(uint64_t key, uint64_t A, uint64_t R);
bool lnh_greq_async(uint64_t key, uint64_t A, uint64_t R);
bool lnh_gr_async(uint64_t key, uint64_t A, uint64_t R);
bool lnh_grls_async(uint64_t key_ls, uint64_t key_gr, uint64_t A, uint64_t R);
2.6.3. Представление структур данных в виде ключей и значений
SPE lnh64 использует беззнаковое сравнение 64 битных ключей для формирования упорядоченной структуры B+дерева. Это позволяет выполнять большинство операций набора команд DISC за O(log8n) операций доступа к памяти.
Таким образом, чтобы реализовать хранение информации в SPE неободимо представить информацию в виде беззнаковых целых чисел.
Частым и востребованным случаем является формирование композитных ключей и значений, состоящих из нескольких полей. При этом старшие разряды определяют порядок сортировки.
В библиотеке leonhardx64_xrt реализованы шаблоны для работы со структурами составных ключей. Обязательным требованием к ним является общий размер, который должен быть равен 64 разрядам как для ключа, так и для значения.
Ниже представлен пример объявления структур композитного ключа и композитного значения:
//Структура данных
#define A 1 //Структура A
//Структура A - ключ
/*
* key[63..32] - Поле 0 - Идентификатор (id)
* key[31..0] - Поле 1 - Порядковый номер (index)
*/
STRUCT(A_key)
{
uint32_t index:32; //Поле 0:
uint32_t id :32; //Поле 1:
};
//Структура A - значение
/*
* value[63..32] - Поле 0 - Атрибут 0
* value[31..24] - Поле 1 - Атрибут 1
* value[23..8] - Поле 2 - Атрибут 2
* value[7..0] - Поле 3 - Атрибут 3
*/
STRUCT(A_value)
{
// Поля объявляются в обратной последовательности (старший байт расположен по старшему адресу)
uint8_t atr3 :8; //Поле 3: Атрибут 3
uint16_t atr2 :16; //Поле 2: Атрибут 2
uint8_t atr1 :8; //Поле 1: Атрибут 1
uint32_t atr0 :32; //Поле 0: Атрибут 0
};
Далее, объявлены макросы INLINE инстанцирования структур и обращения к объединению:
//Макросы для формирования структур inline
#define STRUCT(name) struct name: _base_uint64_t<name>
#define INLINE(type,...) (((type){__VA_ARGS__}).bits)
Макрос STRUCT(name) использует шаблонную структуру _base_uint64_t, которая объявлена в заголовочном файле compose_keys.hxx. Структура типа _base_uint64_t должна занимать в памяти ровно 8 байт, в следствие чего она может быть интерпретирована, как значение стандартного типа uint64_t (т.е. unsigned long long int). С другой стороны, доступ к ней может осуществляться с использованием типа, передаваемого в качестве параметра.
Все поля структуры типа _base_uint64_t размещяются в регистрах процессора.
На основе указанных макросов и объявлений структур можно использовать следующий синтаксис обращения при чтении поля из композитных ключей/значений и их формирования из значений полей:
//Выполнить поиск ключа, ближайшего большего ключу 0x1234
lnh_ngr(A,INLINE(A_key,{.id=0x1234,.index=-1}));
//Прочитать Атрибут 0 найденного значения
atribute0 = get_result_value<A_value>().atr0;
atribute1 = get_result_value<A_value>().atr1;
//Возможно аналогичным образом прочитать ключ результата
index = get_result_key<A_key>().index;
//Вставить новое значение
lnh_ins_async(A,INLINE(A_key,{.id=atr0,.index=0}),INLINE(A_value,{.atr0=0x1234,.atr1=0,.atr2=0,.atr3=0,}));
Подробный пример представлен в проекте dijkstra.c.
3. Практакум №1. Разработка и отладка программ в вычислительном комплексе Тераграф с помощью библиотеки leonhard x64 xrt
Практикум посвящен освоению принципов работы вычислительного комплекса Тераграф и получению практических навыков решения задач обработки множеств на основе гетерогенной вычислительной структуры. В ходе практикума необходимо ознакомиться с типовой структурой двух взаимодействующих программ: хост-подсистемы и программного ядра sw_kernel. Участникам предоставляется доступ к удаленному серверу с ускорительной картой и настроенными средствами сборки проектов, конфигурационный файл для двухъядерной версии микропроцессора Леонард Эйлер, а также библиотека leonhard x64 xrt c открытым исходным кодом.
3.1. Пример взаимодествия устройств
Рассмотрим следующие примеры кода подсистемы и программного ядра, которые мы будем использовать в практикуме. Пример выполняет следующие действия:
-
Хост-подсистема инициализирует ядра GPC:
lnh_inst.load_sw_kernel(argv[2], group, core);, после чего становится возможным запуск обработчиков программного ядра sw_kernel. В практикуме используется версия микропроцессора Леонард Эйлер с одной группой и двумя ядрами GPC, при этом в файле gpc_defs.h разрешено использование только ядра #0 группы #0 (настройка может быть изменена пользователем). -
Хост-подсистема выделяет память под буферы gpc2host_buffer и host2gpc_buffer
-
В буфере host2gpc_buffer инициализируется массив ключей и значений для записи в GPC.
-
Запускается обработчик insert_burst и запускается механизм прямого доступа к памяти для записи host2gpc_buffer в глобальную память группы #0. Последовательность указанных действий может быть обратной: сначала может быть запущен механизм DMA, после чего запускается обработчик.
-
Хост-подсистема ожидает завершения копирования памяти (buf_write_join) для синхронизации процессов.
-
Хост-подсистема передает сообщение с количеством ключей и значений (mq_send(…)).
-
Программное ядро в обработчике insert_burst получает сообщение и выделяет буфер (buffer) для хранения данных в RAM CPE.
-
Программное ядро копирует данные в буфер и последовательно вызывает команду INS микропроцессора lnh64:
lnh_ins_sync(TEST_STRUCTURE,buffer[2*i],buffer[2*i+1]).
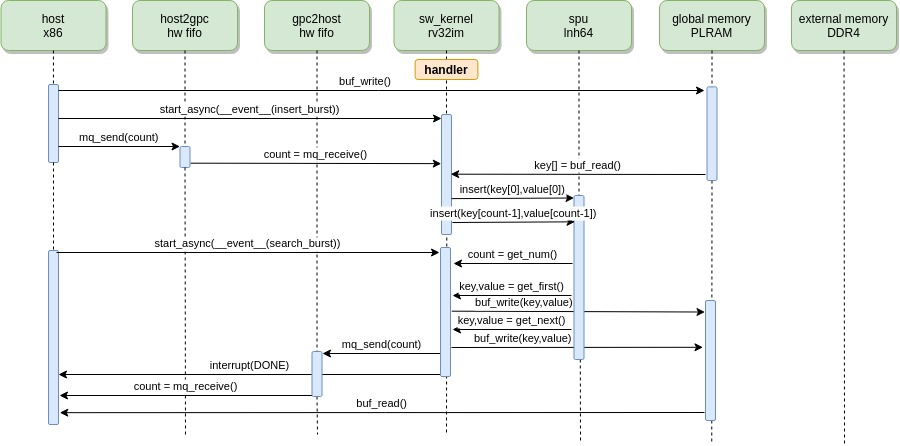 Последовательность действий для реализации пакетной обработки
Последовательность действий для реализации пакетной обработки
-
Далее происходит запуск обработчика для последовательного обхода множества ключей и выдачи их обратно в хост-подсистему.
-
Программное ядро в обработчике search_burst получает количество ключей в структуре (
unsigned int count = lnh_get_num(TEST_STRUCTURE)) -
Обход структуры начинается с выборки минимального ключа (
lnh_get_first(TEST_STRUCTURE)) -
Далее осуществляется запись ключа и значения в буфер для обратной передачи в хост-подсистему.
-
Используя итерационный цикл, или же проверяя результат выполнения функции
lnh_next(TEST_STRUCTURE,lnh_core.result.key)цикл повторяется до обхода всей структуры TEST_STRUCTURE. -
Альтернативно может быть использован следующий код для последовательного обхода структуры:
lnh_get_first(TEST_STRUCTURE);
do {
//lnh_core.result.key - найденный ключ
//lnh_core.result.value - найденное значение
...
} while (lnh_next(TEST_STRUCTURE,lnh_core.result.key));
-
По завершению обхода программное ядро посылает сообщение с количеством переданных ключей и значений.
-
Хост-подсистема ожидает получения сообщения, после чего последовательно проверяет, что ключ в буфере совпадает с ожидаемым.
-
В итоге выдается сообщение о результате тестирования.
Код приложения для хост-подсистемы показан ниже:
// /*
// *
// * Запись множества из BURST key-value и его последовательное чтение через Global Memory Buffer
// *
// */
//Выделение памяти под буферы gpc2host и host2gpc для каждого ядра и группы
uint64_t *host2gpc_buffer[LNH_GROUPS_COUNT][LNH_MAX_CORES_IN_GROUP];
__foreach_core(group, core)
{
host2gpc_buffer[group][core] = (uint64_t*) malloc(2*BURST*sizeof(uint64_t));
}
uint64_t *gpc2host_buffer[LNH_GROUPS_COUNT][LNH_MAX_CORES_IN_GROUP];
__foreach_core(group, core)
{
gpc2host_buffer[group][core] = (uint64_t*) malloc(2*BURST*sizeof(uint64_t));
}
//Создание массива ключей и значений для записи в lnh64
__foreach_core(group, core)
{
for (int i=0;i<BURST;i++) {
//Первый элемент массива uint64_t - key
host2gpc_buffer[group][core][2*i] = rand64();
//Второй uint64_t - value
host2gpc_buffer[group][core][2*i+1] = i;
}
}
//Запуск обработчика insert_burst
__foreach_core(group, core) {
lnh_inst.gpc[group][core]->start_async(__event__(insert_burst));
}
//DMA запись массива host2gpc_buffer в глобальную память
__foreach_core(group, core) {
lnh_inst.gpc[group][core]->buf_write(BURST*2*sizeof(uint64_t),(char*)host2gpc_buffer[group][core]);
}
//Ожидание завершения DMA
__foreach_core(group, core) {
lnh_inst.gpc[group][core]->buf_write_join();
}
//Передать количество key-value
__foreach_core(group, core) {
lnh_inst.gpc[group][core]->mq_send(BURST);
}
//Запуск обработчика для последовательного обхода множества ключей
__foreach_core(group, core) {
lnh_inst.gpc[group][core]->start_async(__event__(search_burst));
}
//Получить количество ключей
unsigned int count[LNH_GROUPS_COUNT][LNH_MAX_CORES_IN_GROUP];
__foreach_core(group, core) {
count[group][core] = lnh_inst.gpc[group][core]->mq_receive();
}
//Прочитать количество ключей
__foreach_core(group, core) {
lnh_inst.gpc[group][core]->buf_read(count[group][core]*2*sizeof(uint64_t),(char*)gpc2host_buffer[group][core]);
}
//Ожидание завершения DMA
__foreach_core(group, core) {
lnh_inst.gpc[group][core]->buf_read_join();
}
bool error = false;
//Проверка целостности данных
__foreach_core(group, core) {
for (int i=0; i<count[group][core]; i++) {
uint64_t key = gpc2host_buffer[group][core][2*i];
uint64_t value = gpc2host_buffer[group][core][2*i+1];
uint64_t orig_key = host2gpc_buffer[group][core][2*value];
if (key != orig_key) {
error = true;
}
}
}
__foreach_core(group, core) {
free(host2gpc_buffer[group][core]);
free(gpc2host_buffer[group][core]);
}
if (!error)
printf("Тест пройден успешно!\n");
else
printf("Тест завершен с ошибкой!\n");
Ниже показаны примеры обработчиков пакетной вставки в структуру insert_burst и пакетного чтения структуры search_burst.
//-------------------------------------------------------------
// Получить пакет из глобальной памяти и отправить в lnh64
//-------------------------------------------------------------
void insert_burst() {
//Удаление данных из структур
lnh_del_str_sync(TEST_STRUCTURE);
//Объявление переменных
unsigned int count = mq_receive();
unsigned int size_in_bytes = 2*count*sizeof(uint64_t);
//Создание буфера для приема пакета
uint64_t *buffer = (uint64_t*)malloc(size_in_bytes);
//Чтение пакета в RAM
buf_read(size_in_bytes, (char*)buffer);
//Обработка пакета - запись
for (int i=0; i<count; i++) {
lnh_ins_sync(TEST_STRUCTURE,buffer[2*i],buffer[2*i+1]);
}
lnh_sync();
free(buffer);
}
//-------------------------------------------------------------
// Обход структуры lnh64 и запись в глобальную память
//-------------------------------------------------------------
void search_burst() {
//Ожидание завершения предыдущих команд
lnh_sync();
//Объявление переменных
unsigned int count = lnh_get_num(TEST_STRUCTURE);
unsigned int size_in_bytes = 2*count*sizeof(uint64_t);
//Создание буфера для приема пакета
uint64_t *buffer = (uint64_t*)malloc(size_in_bytes);
//Выборка минимального ключа
lnh_get_first(TEST_STRUCTURE);
//Запись ключа и значения в буфер
for (int i=0; i<count; i++) {
buffer[2*i] = lnh_core.result.key;
buffer[2*i+1] = lnh_core.result.value;
lnh_next(TEST_STRUCTURE,lnh_core.result.key);
}
//Запись глобальной памяти из RAM
buf_write(size_in_bytes, (char*)buffer);
mq_send(count);
free(buffer);
}
3.2. Подключение к удаленному серверу
Подключение к серверу, на котором будет проходить практикум, выполняется по протоколу ssh в терминальном режиме. Подключиться в серверу можно с использованием терминальных программ, поддерживающих протокол SSH:
- ОС Windows - gitbash, putty.
- В ОС Linux и MacOS - ssh клиент доступен в терминальном режиме в консоли.
Подключение в консоли выполняется при помощи следующей команды:
ssh username@195.19.32.95
где: username - имя пользователя, выдается организаторами практикума каждому участнику.
Обратите внимание, что при троекратном неверном введенном пароле пользователя акаунт будет заблокирован на 2 часа. Рекомендуется прописать ключ пользователя для доступа к серверу с помощью команды
ssh-copy-id username@195.19.32.95, после чего вход на сервер будет осуществляться без ввода пароля.
На сервере установлены все необходимые библиотеки средства для сборки и отладки проекта:
-
набор средств сборки riscv toolchain и экспорт исполняемых файлов в
PATH -
набор библиотек picolib и экспорт в
C_INCLUDE_PATH -
исходный текст проекта taiga и экспорт в переменную окружения
TAIGA_DIR -
библиотека xrt установлена в
/opt/xilinx/xrtучастника практикума все необходимые переменные окружения установлены по-умолчанию.
3.3. Сборка и запуск проекта
После подключения к серверу по протоколу ssh необходимо клонировать репозиторий git с кодом примера, предварительно создав в домашнем каталоге каталог для работы с проектом. Для этого выполните команды:
mkdir worksp
cd worksp
git clone --recursive https://gitlab.com/leonhard-x64-xrt-v2/disc-example.git
Для сборки проекта перейдите в директорию disc-example и выполните команду make:
cd disc-example
make
Результатом выполнения команды станет файлы host_main, sw_kernel_main.rawbinary и leonhard_2cores_267mhz.xclbin в директории проекта верхнего уровня.
Для запуска проекта выполните команду
./host_main leonhard_2cores_267mhz.xclbin sw_kernel_main.rawbinary
Если устройство занято другим проектом, вы можете сбросить его командой
xbutil reset!
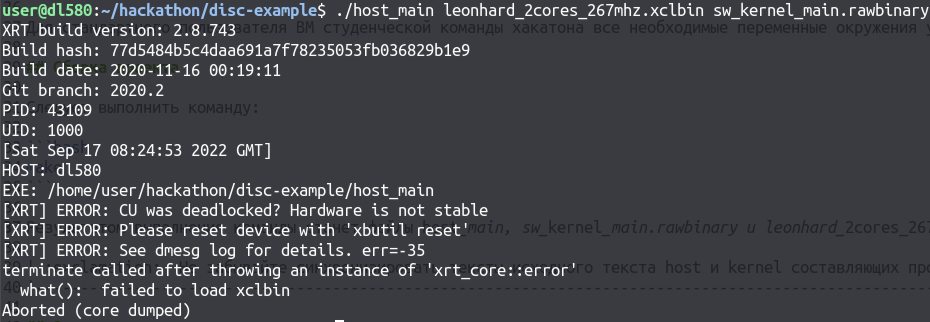 Отказ запуска при блокировке карты
Отказ запуска при блокировке карты
Если устройство не было разблокировано, это означает, что один из пользователей не остановил процесс отладки по
dgb. Вы можете остановить все отладчики в системе и сбросить карту командойsudo /opt/xilinx/overlaybins/reset.sh(даже несмотря на то, что вы не являетесь членом группы sudoers!!!)
В некоторых случаях требуется очистка проекта. Для этого выполните команду:
make clean
3.4. Отладка работы host и sw_kernel
Отладка проекта в консоли позволяет отлаживать код приложений хост-подсистемы и программного ядра sw_kernel с помощью вывода диагностических сообщений.
На сервер практикума возможна отладка с помощью графического пользовательского интерфейса. Для этих целей можно воспользоваться подключением к графическому рабочему столу Linux. На сервере установлены все необходимые средства разработки, и организован множественный доступ к рабочим столам пользователей.
Для доступа к серверу необходимо использовать клиент X2Go (https://wiki.x2go.org/doku.php), который доступен для основных операционных систем: Windows, Linux, OsX, FreeBSD Unix.
Адрес сервера и параметры входа (логин и пароль) соотвествуют параметрам для доступа по протоколу ssh.
В окне программы X2Go создайте новое соединение с указанными параметрами:
-
Поле Хость: ip адрес сервера x2go 195.19.32.95
-
Поле Пользователь: ваш логин
-
SSH порт: 22
-
На вкладке Ввод/Вывод выберите опцию Xinerama
-
На вкладке Ввод/Вывод отмените опцию Установить DPI
Пароль необходимо сменить при первом входе (если вы этого еще не сделали в ssh консоли):
Далее вы будете подключены к рабочему столу KDE операционной системы Ubuntu 18.04:
Запустите Vitis IDE. Создайте новое рабочее пространство (workspace), при этом укажите в качестве рабочего каталога каталог, созданный на шаге 3.3 (в нашем примере - это каталог worksp). Далее выберите пункт Import Project.
Выберите пункт Import Projects from Git
Далее выберите пункт Existing local repository
Далее в поле Directory укажите путь к каталогу, в который клонировался репозиторий на шаге 3.3 (в нашем примере это каталог worksp). Отметьте каталог .git, который появится в поле “Search results”.
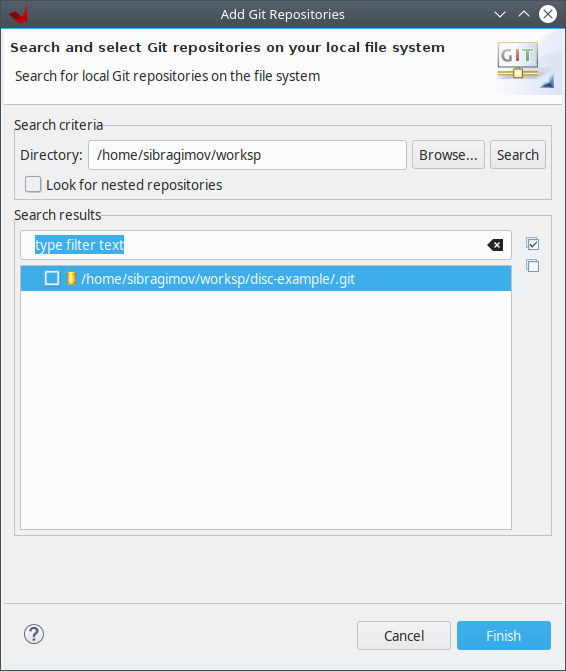
Далее выберите репозиторий disc-example:
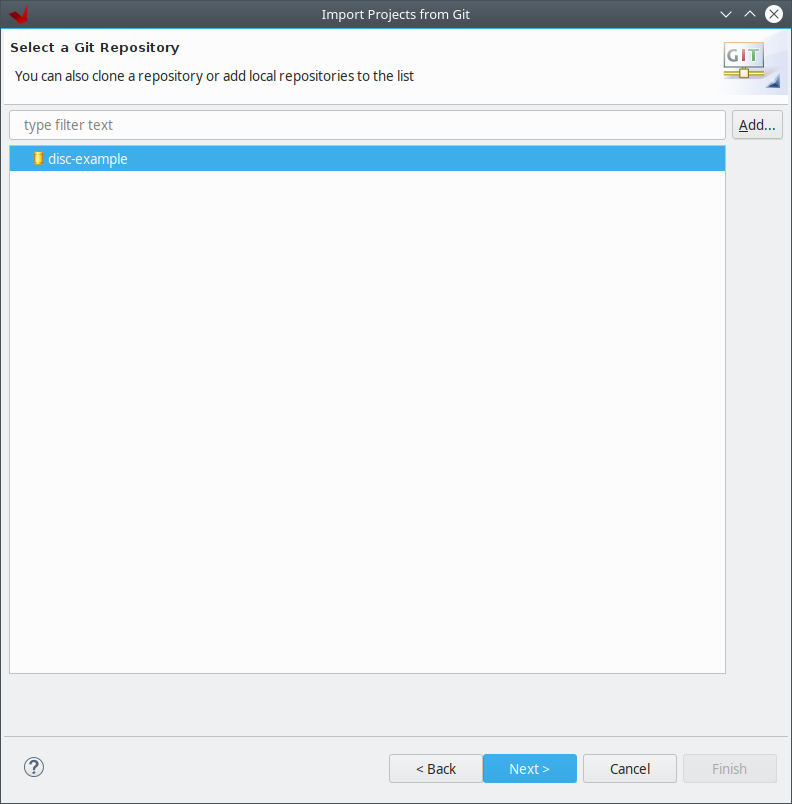
Далее выберите пункт Import existing Eclipse projects
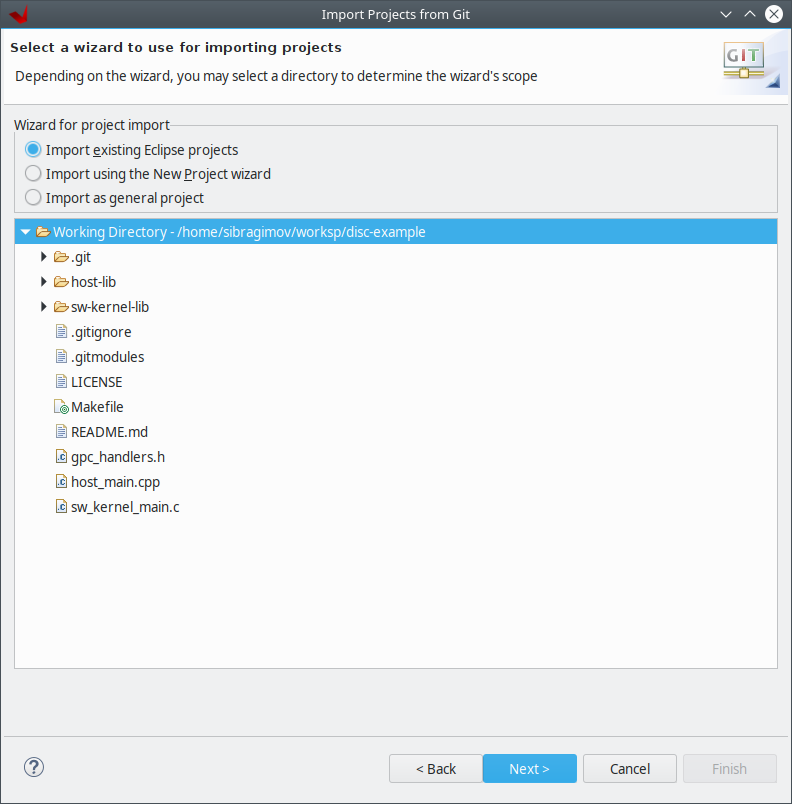
В следующем окне нажмите кнопку Finish. В результате будет создан корневой проект Leonhardx64_xrt_system и проект приложения Leonhardx64_xrt.
Далее для корневого проекта Leonhardx64_xrt_system укажите значение опции Active Build configuration: Hardware.
В результате будет сформирован отладочный проект с настроенными путями к системным библиотекам:
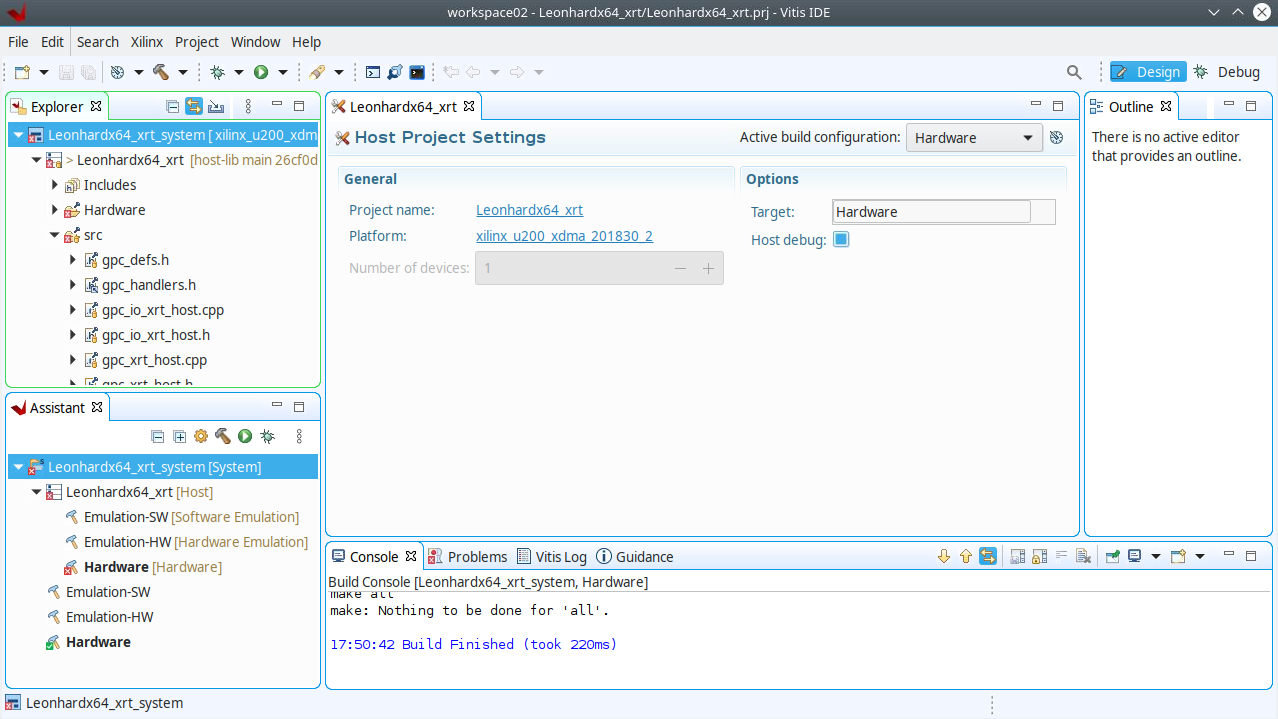
Для успешной сборки проекта требуется добавить путь к заголовочным файлам. Для этого в свойствах проекта Leonhardx64_xrt (Пункт Properties) откройте опцию С/C++ Build -> Settings -> GCC Host Compiler (x86_64) -> Includes -> Include paths (-I).
Добавьте два дополнительных пути:
${workspace_loc}/disc-example/
${workspace_loc}/disc-example/host-lib/src/
Далее можно выполнить сборку проекта.
Для запуска отладки необходимо настроить отладчик. Для этого в пункте Debug (пиктограмма Bug) выберите пункт Debug Configuration.
Далее выберите вариант отладки System Project Debug.
Далее укажите в параметрах запуска Program Arguments путь к файлу конфигурации ${workspace_loc}/disc-example/leonhard_2cores_267mhz.xclbin и программному ядру ${workspace_loc}/disc-example/sw_kernel_main.rawbinary, полученный ранее в пункте 3.1.3. Сборка и запуск проекта.
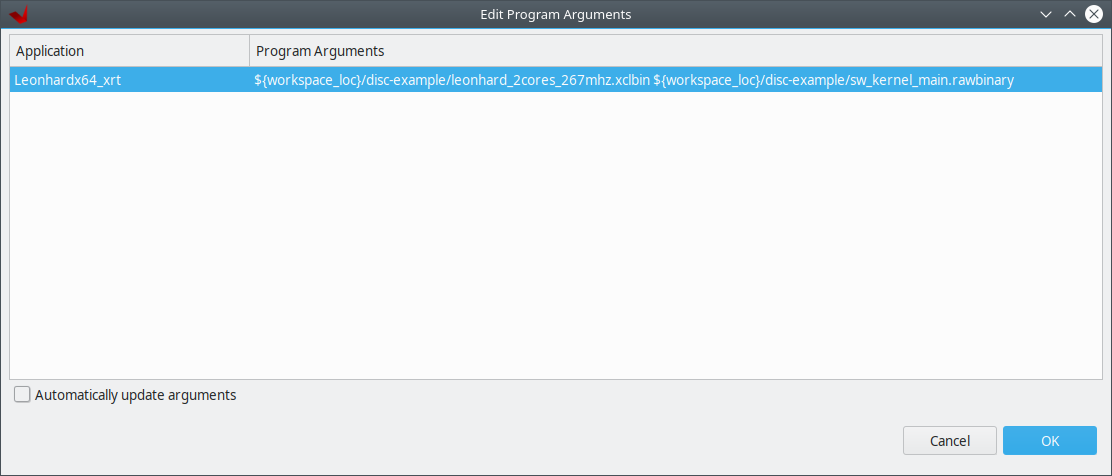
В итоге будет запущена отладка проекта хост-подсистемы.
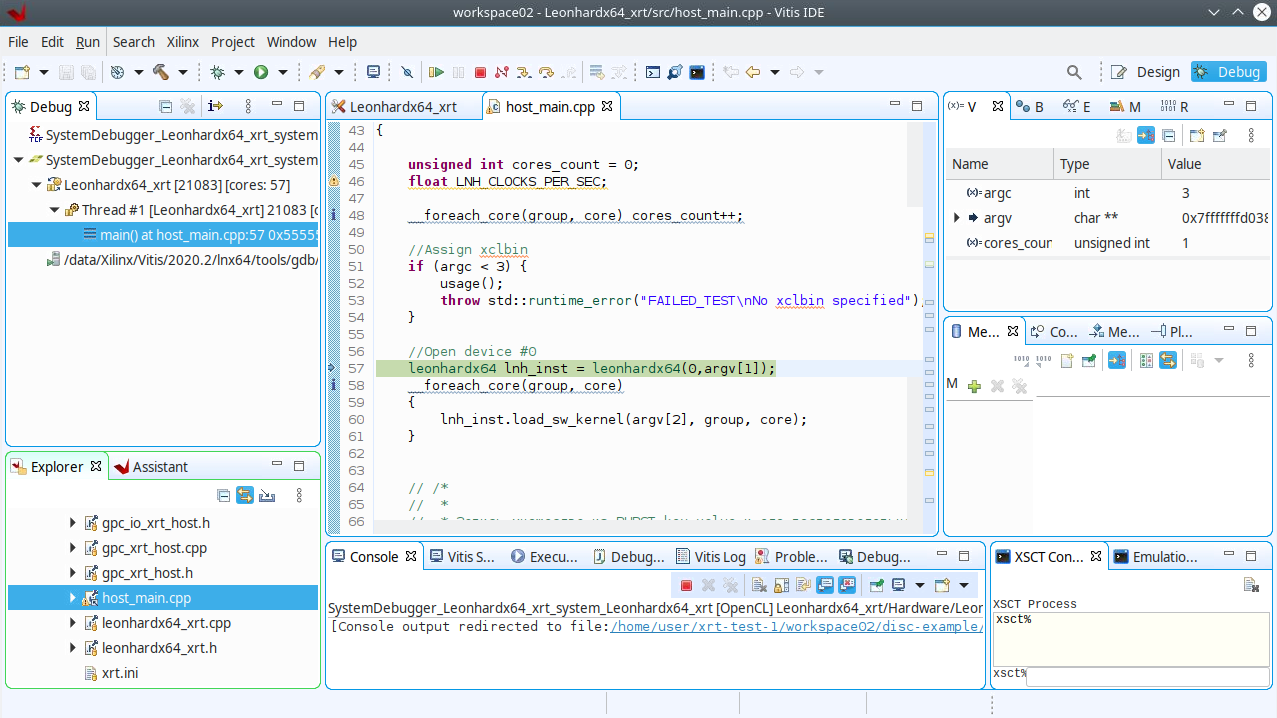
Так как ядро в GPC включено упрощенная версия riscv32, отладка программы sw_kernel может выполняться только на основе вывода сообщений, присланных из sw_kernel в хост-подсистему с помощью очередей MQ. Разработка кода выполняется в любом доступном редакторе (vim,nano,gedit,kate,sublime и прочих).
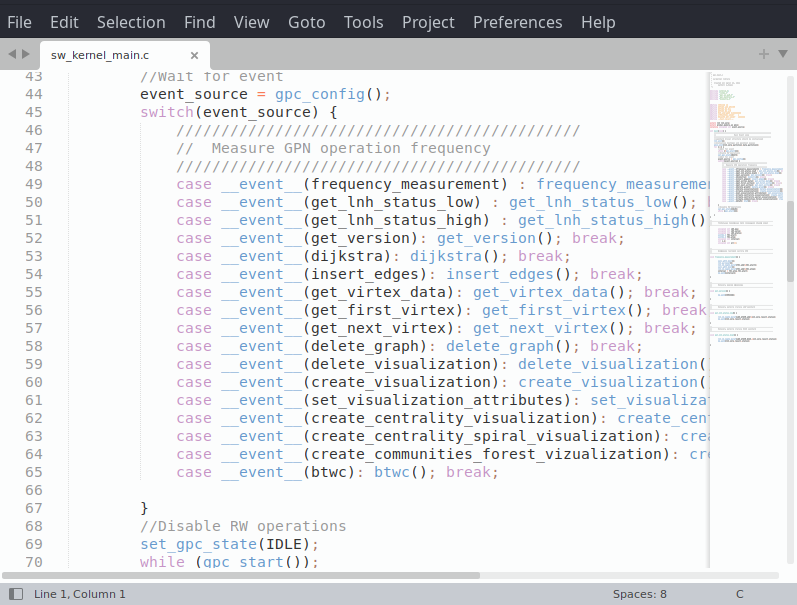
В хост системе полученные сообщения могут выводиться на консоль следующим образом:
#define DEBUG
...
//Полечение сообщений от sw_kernel
#ifdef DEBUG
message = lnh_inst.gpc[group][core]->mq_receive();
while (message!=0) {
printf("Сообщение от sw_kernel: %u\n",message);
message = lnh_inst.gpc[group][core]->mq_receive();
}
#endif
Программное ядро должно в этом случае посылать сообщения, начиная с ненулевого значения mq_send(-1), и заканчивая посылку нулем mq_send(0).
#define DEBUG
...
//Передача отладочный сообщений в xoст-подсистему
#ifdef DEBUG
mq_send(-1);
mq_send(com_u);
mq_send(com_v);
mq_send(com_u_delta_mod);
mq_send(modularity);
mq_send(0);
#endif
3.5. Индивидуальные задания
Разработать программу для хост-подсистемы и обработчики программного ядра, выполняющие следующие действия:
Вариант 1
Сетевой коммутатор на 128 портов. Сформировать в хост-подсистеме и передать в SPE таблицу коммутации из 254 ip адресов 195.19.32.1/24 (адреса 195.19.32.1 .. 195.19.32.254). Каждому адресу поставить в соответствие один из 128 интерфейсов (целые числа 0..127). Выполнить тестирование работы коммутатора, посылая из хост-подсистемы ip адреса и сравнивая полученный от GPC номер интерфейса с ожидаемым.
Вариант 2
Цифровой интерполятор. Сформировать в хост-подсистеме и передать в SPE 256 записей key-value со значениями функции f(x)=x^2 в диапазоне значений x от 0 до 1048576 (где x - ключ, f(x) - значение). Выполнить тестирование работы устройства, посылая из хост-подсистемы значение x и получая от sw_kernel значение f(x). Если указанное значение x не сохранено в SPE, выполнить поиск ближайшего (меньшего или большего) значения к точке x и вернуть соответствующий f(x). Сравнить результат с ожидаемым.
Вариант 3
Устройство формирования индексов SQL INTERSECT. Сформировать в хост-подсистеме и передать в SPE 256 записей множества A (случайные числа в диапазоне 0..1024) и 256 записей множества B (случайные числа в диапазоне 0..1024). Сформировать в SPE множество C = A and B. Выполнить тестирование работы SPE, сравнив набор ключей в множестве C с ожидаемым.
Вариант 4
Цифровой интерполятор ЧПЗ. Сформировать в хост-подсистеме и передать в SPE 256 значений x и функции f(x)=sin(x), имеющие тип double (где x - ключ, f(x) - значение). Для представления чисел double в целочисленном диапазоне использовать функции double ull2double(uint64_t) и uint64_t double2ull(double), входящие в библиотеку sw_kernel-lib. Для случайного значения, сформированного в хост-подсистеме выполнить поиск ближайшего большего, и передать его в хост-подсистему. Выполнить тестирование работы SPE, сравнив результат с ожидаемым.
Вариант 5
Ассоциативная память. Сформировать в хост-подсистеме и передать в SPE 256 случайных ключей и значений (по 64 бит). Выполнить поиск случайного значения ключа. Если результат найден, выдать его на консоль. Если результат не найден, то записать искомый ключ и случайное значение в SPE. Выполнить тестирование работы SPE, сравнив результат с ожидаемым.
Вариант 6
Устройство интегрирования. Сформировать в хост-подсистеме и передать в SPE 256 записей с ключами x и значениями f(x)=x^2 в диапазоне значений x от 0 до 1048576. Передать в sw_kernel числа x1 и x2 (x2>x1). В хост-подсистему вернуть сумму значений f(x) на диапазоне (x1,x2). Сравнить результат с ожидаемым.
Вариант 7
Блок пакетной передачи. Сформировать в хост-подсистеме буфер из 1048575 ключей и значений (по 64 бит). Передать буфер через глобальную память в SPE блоками по 4096 байт и выполнить вставку ключей и значений в SPE. Выполнить обход полученной структуры и результат передать в хост-подсистему блоками по 4096 байт. Сравнить результат с ожидаемым.
Вариант 8
Устройство вычисления обратной функции. Сформировать в хост-подсистеме и передать в SPE 256 записей key-value со значениями функции f(x)=x^2 в диапазоне значений x от 0 до 1048576 (где f(x) - ключ, x - значение). Выполнить тестирование работы устройства, посылая из хост-подсистемы значение f(x) и получая от sw_kernel значение x. Если указанного значения f(x) не сохранено в SPE, выполнить поиск ближайшего (меньшего или большего) значения к f(x) и вернуть соответствующий x. Сравнить результат с ожидаемым.
Вариант 9
Устройство формирования индексов SQL UNION. Сформировать в хост-подсистеме и передать в SPE 256 записей множества A (случайные числа в диапазое 0..1024) и 256 записей множества B (случайные числа в диапазоне 0..1024). Сформировать в SPE множество C = A or B. Выполнить тестирование работы SPE, сравнив набор ключей в множестве C с ожидаемым.
Вариант 10
Коммутатор с QoS. Сформировать в хост-подсистеме и передать в SPE таблицу коммутации из 32 ip адресов 195.19.32.1/24 (адреса 195.19.32.1 .. 195.19.32.32), где для каждого адреса доступны 8 вариантов интерфейсов. Вариант определяется по уровню QoS, принимающему значения от 0 до 7 (в таблице коммутации 256 записей). Выполнить тестирование работы коммутатора, посылая из хост-подсистемы уровень QoS и ip адрес, и сравнивая полученный от GPC номер интерфейса с ожидаемым.
Вариант 11
Устройство формирования индексов SQL EXCEPT. Сформировать в хост-подсистеме и передать в SPE 256 записей множества A (случайные числа в диапазое 0..1024) и 256 записей множества B (случайные числа в диапазоне 0..1024). Сформировать в SPE множество C = A not B. Выполнить тестирование работы SPE, сравнив набор ключей в множестве C с ожидаемым.
Вариант 12
Система сбора сетевой статистики. Сформировать в хост-подсистеме и передать в SPE таблицу из 1024 ip адресов 195.19.32.0/22 (адреса 195.19.32.0 .. 195.19.35.255), где для каждого адреса сформированы четыре 16-ти разрядных счетчика (начальное значение - 0). Далее отправлять из хост-подсистемы номер счетчика и ip адрес. При каждом обращении увеличить соответствующий счетчик на 1. По запросу хост-подсистемы выдать состояние счетчиков для запрошенного ip адреса.
Вариант 13
Устройство управления памятью. Сформировать в SPE таблицу из 1048576 записей свободных страниц (в начальный момент таблица содержит все записи) и вторую таблицу из 1048576 занятых страниц (в начальный момент таблица пуста). При поступлении от хост-подсистемы запроса на выделение страницы удалить запись с минимальным ключом из таблицы свободных страниц и добавить его в таблицу занаятых страниц. Вернуть в хост подсистему номер записанной страницы. При поступлении от хост системы запроса на освобождение страницы произвести обратное действие.
Вариант 14
Устройство хранения темпоральных данных. Сформировать в SPE таблицу хранения темпоральных данных, для которой ключом поиска является текущее время в формате Posix time (количество секунд, прошедшее с 00:00 01.01.1970). От хост-подсистемы запрос на сохранение передается в виде текущего времени (ключ - 32 бит) и некотрого числа (значение - 64 бит). По запросу хост-подсистемы по переданной метке времени выдать число, записанное в ближайшее событии до указанного времени.
Вариант 15
Устройство проверки прав доступа. По запросу от хост-подсистемы, содержащему 64-битный индекс и 64-битный ключ доступа необходимо выполнить поиск на наличие записи с указанным индексом в таблице прав доступа. Если такой индекс имеется, сравнить переданный ключ доступа с сохраненным, и при совпадение ответить хост системе утвердительно (значение 1). Если индекс сохранен, но ключи доступа не совпадают, ответить отрицательно (значение 0). Если индекс не найден, то создать новую запись с полученным индексом и ключом доступа.
Вариант 16
Устройство поиска k ближайших соседей. Сформировать в хост-подсистеме и передать в SPE 256 записей key-value со случайными значениями x и соответствующих им значениях функции f(x)=2 * x^2 - x + 1 в диапазоне значений x от 0 до 1048575 (где x - ключ, f(x) - значение). По запросу хост подсистему выдать ключи x и значения f(x) 32-х ближайших в Эвклидовом пространстве точек x.
Вариант 17
Устройство управления записью в SSD накопитель. Сформировать в SPE таблицу из 1048575 записей с номерами свободных страниц и количеством перезаписей в них (в начальный момент таблица содержит все записи, количество перезаписей равно 0) и вторую таблицу из 1048575 занятых страниц и количеством перезаписей в них (в начальный момент таблица пуста). Для таблиц старшей частью ключа является количество перезаписей, а младшей частью ключа номер страницы. При поступлении от хост-подсистемы запроса на запись удалить из таблицы свободных страниц запись с минимальным количеством перезаписей, увеличить количество перезаписей, и перенести эту информацию в таблицу занятых страниц. Вернуть в хост подсистему номер записанной страницы и ее количество перезаписей. При поступлении от хост системы запроса на освобождение страницы произвести обратное действие, количество перезаписей при этом оставить неизменным.
Вариант 18
Сетевой маршрутизатор на 128 портов. Сформировать в хост-подсистеме и передать в SPE таблицу маршрутизации из 256 произвольно заданных непересекающихся диапазонов ip адресов 195.19.0.0/16 (адреса 195.19.0.0 .. 195.19.255.255). Каждый отрезок задается начальным адресом и маской («/17»..«/31») таким образом, что нет пересечения ip адресов (диапазоны адресов на числовой оси не пересаются). Каждому адресу поставить в соответствие один из 128 интерфесов (целые числа 0..127). При поступлении адреса от хост системы выбрать ближайший меньший (lnh_nsm) диапазон, после чего проверить соответствие ip адреса маске. Если маска соответствует существующему диапазону (адрес попадает в границы диапазона), выдать его хост-подсистеме. Если соответствующего диапазона не существует, выдать 0.
4. Практикум №2. Обработка и визуализация графов в вычислительном комплексе Тераграф
Практикум посвящен освоению принципов представления графов и их обработке с помощью вычислительного комплекса Тераграф. В ходе практикума необходимо ознакомиться с вариантами представления графов в виде объединения структур языка C/C++, изучить и применить на практике примеры решения некоторых задач на графах. По индивидуальному варианту необходимо разработать программу хост-подсистемы и программного ядра sw_kernel, выполняющего обработку и визуализацию графов.
4.1. Конвейер визуализации графов
Визуализация графа — это графическое представление вершин и ребер графа. Визуализация строится на основе исходного графа, но направлена на получение дополнительных атрибутов вершин и ребер: размера, цвета, координат вершин, толщины и геометрии ребер. Помимо этого, в задачи визуализации входит определение масштаба представления визуализации. Для различных по своей природе графов, могут быть более применимы различные варианты визуализации. Таким образом задачи, входящие в последовательность подготовки графа к визуализации, формулируются исходя из эстетических и эвристических критериев. Графы можно визуализировать, используя:
-
2D графическую сцену - наиболее часто применяемый случай, обладающий приемлемой вычислительной сложностью (порядка O(n2 log n));
-
3D графическую сцену - такой вариант позволяет выполнять перемещение камеры наблюдения, что увеличивает возможное количество визуализируемых вершин;
-
Иерархическое представление - граф представляется в виде иерархически вложенных подграфов (уровней), что позволяет более наглядно представить тесно связанные компоненты первоначального графа.
Для визуализации графов было определено несколько показателей качества, позволяющие получить количественные оценки эстетики и удобства графического представления. Алгоритмы раскладки, в большинстве случаев, нацелены на оптимизацию следующих показателей:
-
Меньшее количество пересечений ребер: выравнивание вершин и ребер для получения наименьшего количества пересечений ребер делает визуализацию более понятной и менее запутанной.
-
Минимум наложений вершин и рёбер.
-
Распределение вершин и/или рёбер равномерно.
-
Более тесное расположение смежных вершин.
-
Формирование сообществ вершин из сильно связанных групп вершин.
Для больших графов метод выделения сообществ является предпочтительным, так как позволяет выявить скрытые кластеры вершин, показать центральную вершину сообщества, минимизировать количество внешних связей между сообществами.
Таким образом визуализация графов представляет собой многостадийный алгоритмический процесс. Кратко стадии процесса визуализации представлены на следующем рисунке.

Кратко поясним представленный процесс:
-
Исходный граф может быть представлен различными способами, повышающими эффективность алгоритмов их обработки. Такой граф служит исходными данными для задачи визуализации.
-
На первом этапе формируется граф визуализации, содержащий для каждой вершины и ребра дополнительные атрибуты, значение которых и требуется определить в ходе этого процесса. Могут быть использованы дополнительные атрибуты, позволяющие выявить свойства вершин и более наглядно визуализировать структуру графа. Частым случаем является определение свойства центральности для вершин и ребер. В конечном итоге, для каждой вершины требуется хранить еще и ее координаты (x,y), цвет (color), радиус окружности для представления на сцене визуализации (size).
-
Далее выполняется ряд алгоритмов для определения свойств вершин и ребер. В практикуме используется алгоритм Дейкстры для поиска кратчайших путей, на основе которого рассчитывается центральность вершин.
-
На следующем этапе происходит выделение групп вершин, входящих в так называемые сообществ: связность вершин внутри сообщества превосходит связность за его пределами. Примеры алгоритмов поиска сообществ представлены в библиотеке leonhard x64 xrt.
-
Для каждого сообщества определяется область экрана для его размещения (алгоритмы глобального размещения, global placement).
-
Далее выполняется размещение вершин сообщества внутри каждой выделенной области. На данном этапе применяются алгоритмы, позволяющие представить связи небольшой группы вершин. Частым случаем является применение алгоритмов, основанных на имитации сил притяжения и отталкивания. сформированных на основе информации о вершинах и ребрах.
-
На заключительном этапе происходит передача готового графа визуализации в библиотеку. осуществляющую отрисовку сцены визуализации. В практикуме используется библиотека bokeh.
4.2. Представление информационных моделей алгоритма в виде структур данных
Представление алгоритма обработки множеств и графов в виде операций дискретной математики DISC требует принятия решений о количестве применяемых структур, а также о соответствии информации, используемой в алгоритме, ключам и данным структур. Указанный переход представляет процесс, аналогичный подготовке информации к хранению в базе данных типа “ключ-значение”. В частности, определяются составные ключевые поля, собранные в виде конкатенации данных. В качестве примеров приведем варианты представления графа.
4.2.1. Представление графа G(V,E) списком смежных вершин
Пусть в алгоритме требуется вести обход графа, например, методом поиска в глубину. Тогда основной операцией будет поиск вершин v ∈ Adj[u], инцидентных указанной, и последующий переход к обработке всех связанных вершин. Но, поскольку степень вершин различна, требуется также хранить количество исходящих ребер count. Поле G.KEY хранит номера вершин u и порядковый номер ребра. Поле данных G.VALUE хранит номер инцидентной вершины v и вес ребра w, как показано в Таблице:
Таблица - Пример представления графа G(V,E) списком смежных вершин (G.KEY[u,i], G.VALUE[v,w])
| G.KEY | G.VALUE |
|---|---|
| u,0 | count |
| u,1 | v1,w |
| … | … |
| u,count | vcount,w |
Заметим, что индексная запись (u,0) - (count) может быть перенесена в любое место диапазона индексов, например в последнее (максимальное) значение индекса: (u,-1) - (count).
Представим указанную структуру композитных ключей в виде структур языка С/C++, используя макросы объединения, описанные в разделе 2.6.3. Представление структур данных в виде ключей и значений.
//Структуры данных
#define G 1 //Граф
//Объявление индексов
#define ADJ_C_BITS 32 //количество бит для хранения индекса смежной вершины графа
const unsigned int IDX_MAX=(1ull<<ADJ_C_BITS)-1; //максимальная смежность
#define PTH_IDX IDX_MAX //номер индексной записи о вершине графа
////////////////////////////////////////////////////
// Структура графа тип 1: (G.KEY[u,i], G.VALUE[v,w])
////////////////////////////////////////////////////
//регистр ключа для вершины
/* Struktura 1 - G - описание графа
* key[63..32] - номер вершины
* key[31..0] - индекс записи о вершине (0,1..adj_u-1)
*/
STRUCT(Key){ //Data structure for graph operations
unsigned int index:32; //Поле 1: индекс записи
unsigned int u:32; //Поле 0: номер вершины
} ;
//регистр значения индексной записи для вершины (с индексом PTH_IDX)
/* key[31..0] = PTH_IDX
* key[63..32] = номер вершины u
*/
STRUCT(Attributes){ //Data structure for graph operations
unsigned int count:32; //Поле 1: количество записей
unsigned int any_atrs:32;//Поле 0: дополнительные атрибуты
} ;
//регистр значения для записей о смежных вершинах
/*
* key[31..0] = 0..PTH_IDX-1
* key[63..32] = номер вершины u
* data[31..0] - w[u,v] вес ребра
* atr[63..48] - номер смежной вершины v
*/
STRUCT(Edge) { //Data structure for graph operations
unsigned int v:32; //Поле 1: номер смежной вершины
unsigned int w:32; //Поле 0: вес ребра (u,v)
} ;
Для упрощения синтаксиса описания структур и обращения к их полям мы использум шаблоны, описанные в файле compose_keys.hxx. Макрос объявления структуры выглядит следующим образом:
#define STRUCT(name) struct name: _base_uint64_t<name>. Шаблон структуры _base_uint64_tпозволяет описать 64 битное значение как беззнаковое целое стандартного типа uint64_t и разместить его в регистрах процессора, а не в оперативной памяти. Таким образом достигается большее быстродействие.
4.2.2. Представление графа G(V,E) списком инцидентных ребер
Если в алгоритме необходимо выполнить поиск ребер, соединяющих вершины (u,v), граф может быть представлен другим образом. Поле G.KEY в этом случае составляется из номеров вершин u и v, а поле данных G.VALUE хранит вес ребра w.
Таблица - Пример представления графа G(V,E) списком инцидентных ребер (G.KEY[u,v], G.VALUE[w])
| G.KEY | G.VALUE |
|---|---|
| u,v | w |
Соответствующее описание структуры графа на языке С показано ниже:
//Структуры данных
#define G 1 //Граф
//////////////////////////////////////////////////
// Структура графа тип 2: (G.KEY[u,v], G.VALUE[w])
//////////////////////////////////////////////////
//регистр ключа для вершины
/* Struktura 1 - G - описание графа
* key[63..32] - номер вершины u
* key[31..0] - номер вершины v
*/
STRUCT(Key) { //Data structure for graph operations
unsigned int v:32; //Поле 1: номер вершины v
unsigned int u:32; //Поле 0: номер вершины u
};
//регистр значения записи для ребра (u,v)
/* key[31..0] = дополнительные атрибуты (не использованы)
* key[63..32] = номер вершины u
*/
STRUCT(Attributes) { //Data structure for graph operations
unsigned int w:32; //Поле 1: вес ребра (u,v)
unsigned int any_attrs:32;//Поле 0: дополнительные атрибуты
};
4.2.3. Представление графа G(V,E) упорядоченным списком инцидентных ребер
Часто требуется хранить граф таким образом, чтобы множество ребер было упорядочено по их весу: минимальный ключ должен принадлежать ребру с наименьшим весом. Так как связность в общем случае не является уникальной и в графе могут присутствовать несколько ребер с одинаковым весом, следует использовать более сложный составной ключ. В старшей части ключа должен храниться вес ребра w, а в младшей будут храниться номера вершин (u,v). Т.е. поле G.KEY=(w,u,v). Поле G.VALUE может оставаться пустым, так как необходимая информация об инцидентности вершин и ребер имеется в составном ключе. Однако, в алгоритме может возникнуть необходимость хранить дополнительные атрибуты ребра (флаги, переменные и пр.).
Таблица - Пример представления графа G(V,E) упорядоченным списком инцидентных ребер (G.KEY[w,u,v], G.VALUE[])
| G.KEY | G.VALUE |
|---|---|
| w,u,v | дополнительные атрибуты |
Соответствующее описание структуры графа на языке С показано ниже:
//Структуры данных
#define G 1 //Граф
///////////////////////////////////////////////////
// Структура графа тип 3: (G.KEY[w,u,v], G.VALUE[])
///////////////////////////////////////////////////
//регистр ключа для вершины
/* Struktura 1 - G - описание графа
* key[63..48] - вес ребра (u,v)
* key[47..24] - номер вершины u
* key[23..0] - номер вершины v
*/
STRUCT(Key) { //Data structure for graph operations
unsigned int v:24; //Поле 2: номер вершины v
unsigned int u:24; //Поле 1: номер вершины u
unsigned int w:16; //Поле 0: вес ребра (u,v)
};
//регистр значения записи для ребра (u,v)
/* key[63..0] = дополнительные атрибуты
*/
STRUCT(Attributes) { //Data structure for graph operations
unsigned int any_atr1:32;//Поле 1: дополнительные атрибуты
unsigned int any_atr0:32;//Поле 0: дополнительные атрибуты
};
В зависимости от выполняемых в алгоритме действий возможно использование как одного варианта представления, так и одновременно несколько вариантов.
4.3. Использование библиотеки шаблонов leonhard-x64-xrt-v2 для обработки графов
Для реализация алгоритмов обработки графов необходимо представить операции над множествами (в том числе, множествами вершин и ребер графа) в виде набора команд дискретной математики DISC. Все команды обработки структур данных изменяют регистр статуса, по которому можно определить, было ли выполнение команды успешным (Регистр LNH_STATE, бит SPU_ERROR_FLAG). Результаты, влияющие на работу программы, должны быть учтены в общем алгоритме. После завершения основания команд, основанных на поиске (SEARCH, DELETE, MAX, MIN, NEXT, PREV, NSM, NGR) в очередь данных попадают ключ и значение найденных записей (KEY, VALUE), которые могут быть использованы в алгоритме программного ядра CPE riscv32. Для команд И-ИЛИ-НЕ (пересечение,объединение,дополнение) передаются операнды номеров структур (R,A,B). Операнд R указывает на номер структуры, в которой будет сохранен результат. Структуры A и B используются в И-ИЛИ-НЕ операциях и срезах в качестве исходных.
Таблица - Выполнение базовых операций над структурами данных.
| Действие | Псевдокод вызова команды DISC |
|---|---|
| Поиск по ключу | (KEY,VALUE) = SEARCH(G, Key) |
| Поиск минимульного ключа | (KEY,VALUE) = MIN(G, Key) |
| Поиск максимального ключа | (KEY,VALUE) = MAX(G, Key) |
| Поиск ближайшего меньшего | (KEY,VALUE) = NSM(G, Key) |
| Поиск ближайшего большего | (KEY,VALUE) = NGR(G, Key) |
| Поиск следующего | (KEY,VALUE) = NEXT(G, Key) |
| Поиск предыдущего | (KEY,VALUE) = PREV(G, Key) |
| Добавление | INSERT(G, Key, Data) |
| Удаление | DELETE(G, Key) |
| Объединение структур | OR(Result, Source_A, Source_B) |
| Дополнение структур | NOT(Result, Source_A, Source_B) |
| Пересечение структур | AND(Result, Source_A, Source_B) |
| Срез структуры выше ключа | GR(Result, Source_A, Key) |
| Срез структуры не ниже ключа | GREQ(Result, Source_A, Key) |
| Двойной срез структуры | GRLS(Result, Source_A, Key_A, Key_B) |
После выполнения команд в структуре lnh_core формируется результат в виде ключа,значения и статуса, которые доступны в коде sw_kernel по именам полей:
- lnh_core.result.key - поле ключа (64 бит);
- lnh_core.result.value - поле значения (64 бит);
- lnh_core.result.status - статус выполнения команды (64 бит).
Для того, чтобы извлечь композитные поля структуры, может быть использован следующий вариант приведения полей lnh_core к шаблону структур:
-
Чтение поля из композитного ключа выполняется с помощью следующего шаблона:
get_result_key<ИМЯ_СТРУКТУРЫ>().ИМЯ_ПОЛЯ;. Например:weight = get_result_key<Graph::Key>().u; -
Чтение поля из композитного значения выполняется аналогично с помощью следующего шаблона:
get_result_value<ИМЯ_СТРУКТУРЫ>().ИМЯ_ПОЛЯ;. Например:var = get_result_value<Graph::Edge>().w; -
Запись композитных полей в структуру осуществляется с помощью стандартного шаблона инициализации структуры:
ИМЯ_СТРУКТУРЫ{.ИМЯ_ПОЛЯ1=ЗНАЧЕНИЕ, .ИМЯ_ПОЛЯ2=ЗНАЧЕНИЕ}, например:Graph::Key{.index=BASE_IDX, .u=u}
Для упрощения разработки алгоритмов на графах, а также контроля корректности синтаксических конструкций работы с ядром lnh64 была разработана расширенная версия библиотеки leonhard x64 xrt iterators. По данной ссылке доступны дополнительные заголовочные и cpp файлы, в которых собраны шаблоны описаний типовых структур графа и различных сервисных структур (очередей, деревьев и т.д.), необходимых для обработки графов и их визуалиации. Описание структур приведено в файле graph_iterators.hxx
Описание каждой из перечисленных ниже структур состоит из следующих секций:
-
Описание константного значения номера структуры struct_number при хранении в ядре lnh64. Данный параметр передается при инициализации структуры и остается неизменным в дальнейшем, вплоть до удаления информации из памяти lnh64/ Допускаются указывать номера структур, не занятые другой информацией, в диапазоне 1..7.
-
Описание индексов и констант, используемых при описании ключей. Целесообразно использовать индексы в конце диапазона рабочих значений.
-
Описание множества шаблонов ключей и значений.
-
Связывание типов ключей и значений с помощью макросов DEFINE_DEFAULT_KEYVAL(<КЛЮЧ>,<ЗНАЧЕНИЕ>) и DEFINE_KEYVAL(<КЛЮЧ>,<ЗНАЧЕНИЕ>). Макросы служат для создания синтаксических ограничений, которые запрещают программисту использовать иные сочетания. Например, если указан макрос DEFINE_DEFAULT_KEYVAL(Key_type,Value_type), то результатов выполнения команды выборки минимального ключа множеств будет структура типа Key_type.
-
Область объявления итераторов над структурой.
//Объявление номера структуры для зранения графа в lnh64
#define G 1 //Граф
...
//Инициализация структуры и запись номера структуры lnh64
constexpr Graph G1(G);
...
// Получить ключ записи с минимальным значением ключа
auto key = G1.get_first().key();
// key имеет тип, указанный в качестве DEFINE_DEFAULT_KEYVAL для ключа
Ниже приведены описания структур и шаблонов ключей и значений, указанных в них. Также приведем перечень итераторов для каждой из структур.
Таблица - Шаблон структуры для представления графа.
| Структура/-Шаблон/* Поле | Назначение |
|---|---|
| Graph | Представление графа G(V,E) списком смежных вершин |
| Key | Поле ключа для записи о ребре (используется по умолчанию) |
| index | Индекс записи (0..index_max-2) |
| u | Номер вершины в графе |
| Path_key | Поле ключа для записи о кратчайшем пути и центральности |
| index | Индекс записи = index_max |
| u | Номер вершины в графе |
| Base_key | Поле ключа для записи атрибутов вершины |
| index | Индекс записи = index_max-1 |
| u | Номер вершины в графе |
| Viz_key | Поле ключа для записи об атрибутах визуализации |
| index | Индекс записи = index_max-2 |
| u | Номер вершины в графе |
| Edge | Поле значения для записи о ребре (используется по умолчанию) |
| v | Номер смежной вершины |
| w | Вес ребра |
| attr | Дополнительные атрибуты ребра |
| Shortest_path | Поле значения для записи о кратчайшем пути до вершины |
| du | Кратчайший путь от данной вершины до стартовой вершины |
| btwc | Центральность вершины |
| Attributes | Поле значения для записи атрибутов |
| pu | Номер предшествующей вершины в кратчайшем пути |
| eQ | Флаг хранения вершины в очереди (используется в алгоритме Дейкстры) |
| adj_c | Количество ребер вершины |
| vAttributes | Поле значения для аписи атрибутов визуализации |
| x | Координата x для визуализации |
| y | Координата y для визуализации |
| size | Размер окружности для визуализации вершины |
| color | Цвет окружности для визуализации вершины |
Для структуры графа определены следующие синтаксические ограничения:
//Обязательная типизация
DEFINE_DEFAULT_KEYVAL(Key, Edge)
//Дополнительная типизация
DEFINE_KEYVAL(Base_key, Attributes)
DEFINE_KEYVAL(Path_key, Shortest_path)
DEFINE_KEYVAL(Viz_key, vAttributes)
Для структуры графа определены итераторы:
-
Итератор вершин графа.
-
Итератор ребер для вершины графа.
Пример использования итератора вершин графа:
//Для каждой вершины графа
for (unsigned int v : virtex_range{G1}) {
...
}
Пример использования итератора ребер для вершины графа:
for (auto [adj, wu, attr] : edge_range(G1, v)) {
...
}
Например, можно использовать следующий пример для определения количества ребер графа и вычисления средего веса ребра:
uint32_t weight_sum=0; //сумма весов ребер
uint32_t edge_count=0; //количество ребер
//Обход всех вершин графа и вычисление среднего веса ребра
for (auto com_u : virtex_range{G1}) {
//Для каждого ребра определить его вес
for (auto [com_v, wu, attr] : edge_range(G1, com_u)) {
weight_sum += wu;
edge_count++;
}
}
uint32_t weight_average = weight_sum/edge_count;
В ряде алгоритмов требуется использовать очередь вершин. Для этого в библиотеке создана следующая структура:
Таблица - Шаблон структуры для представления очереди вершин графа.
| Структура / Шаблон / Поле | Назначение |
|---|---|
| Queue | Структура очереди |
| Record | Поле ключа для записи очереди |
| id | Номер вершины графа |
| du | Кратчайший путь (используется в алгоритме Дейкстры) |
| Attributes | Поле зачения для атрибутов записи |
| attr | Атрибуты записи |
Синтаксические ограничения на типы для очереди следующие:
//Обязательная типизация
DEFINE_DEFAULT_KEYVAL(Record, Attributes)
Для очереди реализован итераторы, позволяющие выполнить обход в прямом (в сторону увеличения значений ключа), так и о обратном порядке. Оба итератора выдают значения ключа для записи, а также удаляют найденную запись из очереди (значение читается только один раз).
! Обход очереди можут осуществляться как в прямом порядке (увеличение ключей), так и в обратном (уменьшение ключей). При этом возможны два варианта перехода к следующей записи очереди: поиск следующего ключа по порядку, или удаление найденного элемента из очереди.
Приведем все четыре варианта обхода очереди.
В некоторых случаях требуется модифицировать очередь и выбирать записи из хвоста или головы очереди. Для этого можно использовать методы структуры очереди begin или rbegin (головная, первая запись очереди), rend (хвост, последняя вершина очереди), а также функцию удаления элемента из очереди erase. Пример использования итератора обхода очереди в прямом порядке с удалением записи из очереди:
//обход всех вершины графа
while(auto q_it = Q.begin()) { //Выбирается первая запись очереди
Q.erase(q_it);
auto [u, du] = *q_it;
//Получение суммарной длины ребер
du_sum += du;
...
}
Пример использования итератора обхода очереди в обратном порядке с удалением (итератор rbegin):
//обход всех вершины графа
while(auto q_it = Q.rbegin()) { //Выбирается поседняя запись очереди
Q.erase(q_it);
auto [u, du] = *q_it;
//Получение суммарной длины ребер
du_sum += du;
...
}
Пример использования итератора обхода очереди в прямом порядке без изменения очереди:
//обход всех вершины графа
for(auto [u, du]:Q) { //Выбирается следующая запись очереди
//Получение суммарной длины ребер
du_sum += du;
}
Пример использования итератора обхода очереди в обратном порядке без изменения очереди:
//обход всех вершины графа
for(auto [u, du]:reverse{Q}) { //Выбирается следующая запись очереди
//Получение суммарной длины ребер
du_sum += du;
...
}
Для визуализации графов часто требуется объединить вершины в сообщества по свойству модулярности (смотри алгоритм в разделе “4.4.3.1. Выделение сообществ на основе алгоритма MultiLevel”). Следующие структуры используются для построения сообществ. а также для размещения сообществ вершин в прямоугольных областях экрана.
Таблица - Шаблон структуры для представления сообществ.
| Структура / Шаблон / Поле | Назначение |
|---|---|
| Community | Структура сообществ по модулярности (для визуализации) |
| Key | Поле ключа для сообщества |
| adj | Количество ребер сообщества |
| id | Номер сообщества |
| Value | Поле зачения для атрибутов сообщества |
| first_virtex | Номер начальной вершины графа, принадлежащей сообществу |
| last_virtex | Номер конечной вершины графа, принадлежащей сообществу |
| id | Номер сообщества |
Синтаксические ограничения на типы для очереди следующие:
//Обязательная типизация
DEFINE_DEFAULT_KEYVAL(Key, Value)
Для структуры сообществ определены итераторы:
-
Итератор обхода сообществ
-
Итератор обхода вершин графа, входящий в сообщество.
Пример кода для обхода всех сообществ, хранимых в структуре cG1:
for (auto cmty : community_range{cG1}) {
...
}
Для обхода всех вершин графа одного сообщества может быть испольован следующий код:
for (auto u : community_member_range(cG1, cmty)) {
...
}
Следующая структура используется для раскладки сообществ в прямоугодьняе области. ДЛя этого строится дерево сообществ, после чего экран делится для левого и правого поддеревьев пропорционально количеству вершин в них. Таким образом получается иерархически и итерационно разместить тесно связанные сообщества ближе друг к другу.
Таблица - Шаблон структуры для представления дерева сообществ.
| Структура / Шаблон / Поле | Назначение |
|---|---|
| cTree | Структура дерева сообществ по модулярности (для визуализации) |
| Key | Поле ключа для сообщества |
| adj | Количество ребер сообщества |
| com_id | Номер сообщества |
| Vcount_key | Поле ключа для записи атрибутов сообщества |
| index | Индекс записи об атрибутах сообщества, index = index_max |
| com_id | Номер сообщества |
| XY_key | Поле ключа для записи границ визуализации сообщества |
| index | Индекс записи о границах поля визуализации, index = index_max-1 |
| com_id | Номер сообщества |
| Value | Поле зачения для атрибутов сообщества |
| left_leaf | Номер сообщества левого листа в дереве |
| right_leaf | Номер сообщества правого листа в дереве |
| Vcount_value | Поле значения для записи атрибутов сообщества |
| v_count | Количество вершин графа, входящих в сообщество |
| is_leaf | Флаг, указывающий на запись дерева типа “лист” |
| XY_value | Поле значения для записи атрибутов визуализации сообщества |
| x0 | Координата x левого нижнего угла прямоугольной области визуализации |
| y0 | Координата y левого нижнего угла прямоугольной области визуализации |
| x1 | Координата x правого верхнего угла прямоугольной области визуализации |
| y1 | Координата y правого верхнего угла прямоугольной области визуализации |
Для дерева сообществ определена следующая синтаксическая типизация:
//Обязательная типизация
DEFINE_DEFAULT_KEYVAL(Key, Value)
//Дополнительная типизация
DEFINE_KEYVAL(Vcount_key, Vcount_value)
DEFINE_KEYVAL(XY_key, XY_value)
Итератор для структуры дерева сообществ позволяет выполнить обход всех сообществ:
for (auto community : ctree_range(cT1)) {
...
}
Следующие две структур представляют собой прямую и обратные очереди, в которых записи упорядочены по значению изменения модулярности (демодулярности), возникающей при объединении двух сообществ. Таким образом на каждом шаге алгоритма можно выполнить поиск двух сообществ, в наибольше степени связанных между собой в сравнении со средним значением связности сообществ аналогичной размерности.
Структур mQueue упорядочивает записи по значению модулярности, в то время как в атрибутах записей хранит номера сообществ. Структура iQueue, наоборот, представляет записи по ключам сообществ, а в поле значения хранит модулярность (обратный формат записи).
Таблица - Шаблон структуры для представления очереди демодулярности (изменения модулярности при объединении сообществ u и v).
| Структура / Шаблон / Поле | Назначение |
|---|---|
| mQueue | Структура очереди демодулярности (для визуализации) |
| Modularity | Поле ключа для хранения записи о номере сообщества |
| index | Номер записи (всегда = 1) |
| id | Индекс записи с значением дельтамодулярности delta_mod |
| delta_mod | Значение демодулярности |
| Modularity_ext | Поле ключа дополнительной записи атрибутов |
| index | Номер записи (всегда = 0) |
| id | Индекс записи с значением дельтамодулярности delta_mod |
| delta_mod | Значение демодулярности |
| Communities | Поле зачения для атрибутов сообщества |
| com_u | Номер сообщества u |
| com_v | Номер сообщества v |
| Attributes | Поле ключа для записи границ визуализации сообщества |
| w_u_v | Количество ребер, связывающих сообщества u и v |
Для очереди модулярности заданы следующие соответствия типов:
//Дополнительная типизация
DEFINE_DEFAULT_KEYVAL(Modularity, Communities)
//Обязательная типизация
DEFINE_KEYVAL(Modularity_ext, Attributes)
Таблица - Шаблон структуры для представления обратой очереди демодулярности.
| Структура / Шаблон / Поле | Назначение |
|---|---|
| iQueue | Структура обратной очереди демодулярности (для визуализации) |
| Communities | Поле ключа для атрибутов сообщества (обратная запись) |
| com_u | Номер сообщества u |
| com_v | Номер сообщества v |
| Modularity | Поле значения для хранения записи о номере сообщества |
| index | Номер записи (всегда = 1) |
| id | Индекс записи с значением дельтамодулярности delta_mod |
| delta_mod | Значение демодулярности |
Для структуры обратной очереди задано ограничение по умолчанию:
//Обязательная типизация
DEFINE_DEFAULT_KEYVAL(Communities, Modularity)
Для очередей модулярности и демоделярности задан единый итератор, позволяющй обойти все элементы очереди модулярности в убывающем порядке демодулярности. Удаление записи о сообществе из одной очереди автоматически приводит к удалению соотвествующей записи и во второйо очереди. При этом итаратором рассматривается только те записи, для которых демодулярность положительная или нулевая. Итератор принимает в качестве параметров номера структур прямой и обратной очереди демодулярности
// Инициализация итератора
mqueue_range mqr{mQ, iQ};
//Основной цикл
while (auto mq_it = mqr.rbegin()) {
//u,v - номера объединяемых сообществ
//w_u_v - атрибут связности u и v
auto [com_v, com_u, com_u_index_val, com_u_delta_mod, w_u_v] = *mq_it;
//Удалить запись о модулярности связи сообществ u<->v
mqr.erase(mq_it);
...
}
Для обратной обратной очереди демодулярности реализован дополнительный итератор, позволяющий выполнить обход всех сообществ, связанных с указанным сообществом v:
for (auto mod_record : iqueue_range(iQ1,v)) {
...
}
Далее все примеры будут испольщовать указанные сруктуры и их итераторы.
4.4. Примеры реализации алгоритмов на графах
4.4.1. Алгоритм Дейкстры поиска кратчайшего пути
Рассмотрим реализацию алгоритма Дейкстры для поиска кратчайших путей на графе. Этот алгоритм используется, в частности, для сетевой маршрутизации и поиска кратчайших маршрутов в навигационных системах.
Задача формулируется следующим образом. Для взвешенного ориентированного графа G(V,E) без петель и дуг отрицательного веса найти кратчайшие пути от некоторой вершины до всех остальных. Пусть: w[u][v] - вес ребра, соединяющего вершину u и v; Adj[u] — множество вершин, смежных с u; s — исходная вершина; Q — множество вершин, которые осталось рассмотреть для поиска кратчайших путей; d[u] — расстояние от вершины s до вершины u; p[u] — вершина, предшествующая вершине u в кратчайшем пути от s до u.
В начальный момент времени множество Q состоит из всех вершин графа: Q=V. Алгоритм предполагает на каждом шаге поиск в множестве Q вершины u с наименьшим значением d[u], ее удаление из Q, а также вычислению значений d[v] для всех связанных с u вершин, входящих в Q. Если полученная длина пути короче ранее найденной, то она модифицируется, и сохраняется новый маршрут p[v] через вершину u. В итоге, когда будут просмотрены все вершины и Q останется пуст, в p[u] окажется кратчайший маршрут, а в d[u] — его длина. Псевдокод алгоритма представлен ниже:
Дейкстра(s)
Q = V
d[s] = 0
p[s] = 0
ЦИКЛ ПОКА
Для всех u ∈ V, u /= s
d[u] = ∞;
ВСЕ ЦИКЛ ПОКА
ЦИКЛ ПОКА Q /= ∅
ПОИСК (u ∈ Q с минимальным значением d[u])
Q=Q \ u;
ЦИКЛ ПОКА
Для всех вершин v ∈ Adj[u]
ЕСЛИ ( (v ∈ Q) и (d[v] > d[u] + w[u][v]) ) ТО
d[v] = d[u] + w[u][v];
p[v] = u;
ВСЕ ЕСЛИ
ВСЕ ЦИКЛ ПОКА
ВСЕ ЦИКЛ ПОКА
В алгоритме необходимо реализовать структуры данных для хранения графа G и очередь из вершин Q по порядку длины путей d[u] до стартовой вершины. Как говорилось ранее, для вычислительной системы с набором команд дискретной математики требуется представить G и Q в виде структур с 64x битными ключами и значениями.
Примем следующие обозначения: S.KEY(k1,..,kn) является составным ключом поиска в некоторой структуре S, состоящим из полей k1,..,kn; S.VALUE(d1,…,dn) являются данными для структуры S, состоящими из полей d1,…,dn. Доступ к конкретным полям данных может быть показан в псевдокоде алгоритма с помощью модификатора, т.е. как S.VALUE.d1. Например, изменение поля x в составном поле данных указывается как S.VALUE.x=10.
Множество Q используется для поиска вершины с наименьшим показателем d[u]. Т.к. значение d[u] для разных вершин в структуре Q может быть одинаковым, то d[u] не может являться ключом. В качестве ключа может быть выбрана пара значений Q.KEY=(d[u],u). Это обеспечивает не только поиск вершины с минимальным d[u], но и выбор вершины с наименьшим номером из нескольких возможных вариантов. Поле данных структуры Q не используется: Q.VALUE=(0).
Исходный граф G применяется в алгоритме для определения списка смежных вершин и другой информации, соответствующей каждой вершине. Ключом поиска в структуре G будет являться уникальный номер вершины в графе G: G.KEY=(u). Данными для структуры G является множество смежных вершин Adj[u], массив длин путей для них w[u], найденное кратчайшее расстояние d[u], маршрут p[u], а также бит принадлежности вершины к множеству Q: т.е. G.VALUE=(Adj[u],w[u],d[u],p[u],u∈Q). Пояснить использование этих структур можно на примере поиска кратчайших путей для графа, представленного на рисунке:
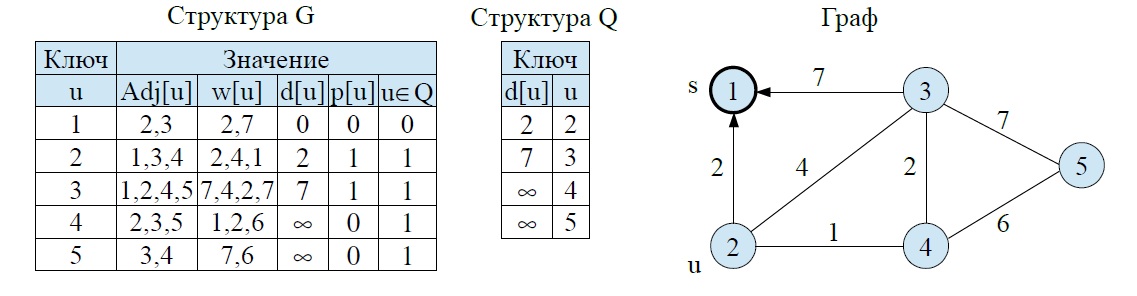
На первом шаге алгоритма из структуры Q выбирается минимальный ключ Q.KEY=(0,1) и по нему определяется код u, соответствующий вершине s=1. Для этой вершины в структуре G выбирается строка и определяются поля Adj[u],w[u],d[u],p[u],u∈Q.
Найденная строка исключается из структуры Q по известному ключу Q.KEY=(d[u],u). Далее, для каждой вершины v из множества Adj[u] по структуре G определяется принадлежность к множеству Q (параметр u∈Q). Если он равен 1, то проверяется условие d[v]=d[u]+w[u][v], где w[u][v] — один из элементов множества w[u], соответствующий ребру между u и v.
Цикл повторяется до полного опустошения структуры Q. В результате будут определены кратчайшие пути и их длины для всех вершин. Состояние структур после выполнения всех итераций показано на следующем рисунке.
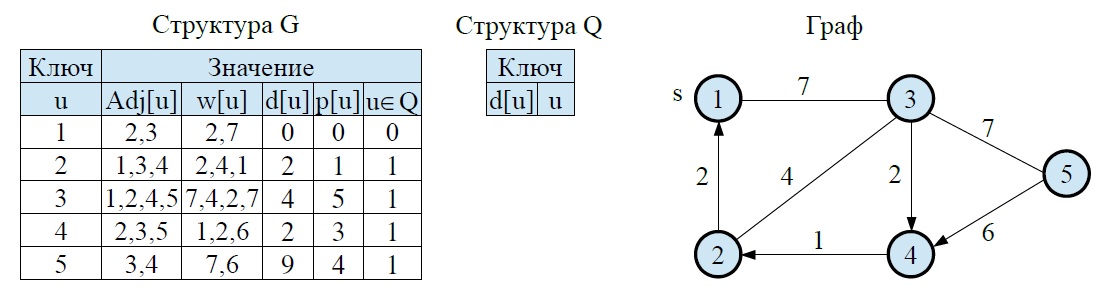
Указанные на рисунке структуры могут быть объявлены следующим образом:
struct Graph {
using virtex_t = uint32_t;
int struct_number;
constexpr Graph(int struct_number) : struct_number(struct_number) {}
static const uint32_t adj_c_bits = 32;
static const uint32_t idx_max = (1ull << adj_c_bits) - 1;
static const uint32_t pth_idx = idx_max;
static const uint32_t base_idx = idx_max - 1;
static const uint32_t viz_idx = idx_max - 2;
//регистр ключа для вершины:
/* STRUCT(u_key) - G - описание графа
* key[63..32] - номер вершины
* key[31..0] - индекс записи о вершине (0,1..adj_u)
*/
STRUCT(Key) {
unsigned int index: 32;
virtex_t u: 32;
};
STRUCT(Path_key) {
unsigned int index: 32 = pth_idx;
virtex_t u: 32;
};
STRUCT(Base_key) {
unsigned int index: 32 = base_idx;
virtex_t u: 32;
};
//граф визуализации
STRUCT(Viz_key) {
unsigned int index: 32 = viz_idx;
virtex_t u: 32;
};
//регистр значения для записей о смежных вершинах:
STRUCT(Edge) {
virtex_t v: 32;
short int w: 16;
short int attr: 16;
};
//регистр значения индексной записи для вершины (с индексом PTH_IDX):
STRUCT(Shortest_path) {
virtex_t du: 32;
unsigned int btwc: 32;
};
//регистр значения атрибутов для вершины с индексом BASE_IDX: STRUCT(u_attributes)
STRUCT(Attributes) {
unsigned int pu: 32;
bool eQ: 8;
int non: 8 = 0;
short int adj_c: 16;
};
//регистр значения для записи атрибутов визуализации вершинах
STRUCT(vAttributes) { //Data structure for graph operations
unsigned short int x: 16; //Поле 1: координата x [0..64K]
unsigned short int y: 16; //Поле 2: координата y [0..64K]
unsigned short int size: 8; //Поле 3: размер [0..255]
unsigned int color: 24; //Поле 4: цвет [0x000000..0xFFFFFF]
};
//Обязательная типизация
DEFINE_DEFAULT_KEYVAL(Key, Edge)
//Дополнительная типизация
DEFINE_KEYVAL(Base_key, Attributes)
DEFINE_KEYVAL(Path_key, Shortest_path)
DEFINE_KEYVAL(Viz_key, vAttributes)
};
Далее рассмотрим код, реализующий алгоритм Дейкстры в программном ядре CPE.
void dijkstra_core(unsigned int start_virtex) {
//Очистка очереди
Q.del_str_async();
//добавление стартовой вершины с du=0
Q.ins_async(Queue::Record{.id = start_virtex, .du = 0}, Queue::Attributes{});
//Get btwc to store it again
auto [du, btwc] = G.search(Graph::Path_key{.u = start_virtex}).value();
//Save du for start virtex
G.ins_async(Graph::Path_key{.u = start_virtex}, Graph::Shortest_path{.du = 0, .btwc = btwc});
//обход всех вершины графа
while(auto q_it = Q.begin()) {
Q.erase(q_it);
auto [u, du] = *q_it;
//Get pu, |Adj|, eQ
auto result = G.search(Graph::Base_key{.u = u});
auto [pu, eQ, non, adj_c] = result.value();
// Clear eQ
G.ins_async(result.key(), Graph::Attributes{.pu = pu, .eQ = false, .non = 0, .adj_c = adj_c});
//For each Adj
for (auto [adj, wu, attr] : edge_range(G, u)) {
//Get information about Adj[i]
auto [adj_pu, eQc, non, count] = G.search(Graph::Base_key{.u = adj}).value();
auto [dv, btwc] = G.search(Graph::Path_key{.u = adj}).value();
//Change distance
if (dv > (du + wu)) {
if (eQc) {
//if not loopback, push to Q
if (dv != Graph::inf) {
Q.del_async(Queue::Record{.id = adj, .du = dv});
}
Q.ins_async(Queue::Record{.id = adj, .du = du + wu}, Queue::Attributes{});
}
//change du
G.ins_async(Graph::Path_key{.u = adj}, Graph::Shortest_path{.du = du + wu, .btwc = btwc});
//change pu
G.ins_async(Graph::Base_key{.u = adj}, Graph::Attributes{.pu = u, .eQ = eQc, .non = 0, .adj_c = count});
}
}
}
}
Обратите внимание, что в структуре графа для каждой вершины выделены дополнительные индексы pth_idx и viz_idx и поле btwc, которые будут использованы позднее в алгоритме вычисления центральности и алгоритме визуализации. В показанном примере поле центральности копируется из ранее найденных кратчайших путей, т.е. накапливается.
auto [du, btwc] = G1.search(Graph::Path_key{.u = start_virtex}).value();
G1.ins_async(Graph::Path_key{.u = start_virtex}, Graph::Shortest_path{.du = 0, .btwc = btwc});
4.4.2. Алгоритм поиска центральности
Для многих сетевых структур необходимо определить относительную важность входящих в нее узлов. Например, загруженность узла связи в компьютерной сети определяется как суммарное число кратчайших путей между всеми остальными узлами, которые проходят через узел i:
где:
σs,t(i) – число кратчайших путей из узла s в узел t через узел i;
σs,t – общее число кратчайших путей между всеми парами s и t.
Эту величину можно считать индикатором влиятельности людей в социальной сети, или же степень участия белка в различные реакции обмена веществ. Эта величина также важна в изучении транспортных потоков и обычно называется нагрузкой (загруженностью) узла (или связи), поскольку характеризует долю проходящих через узел кратчайших путей. Узлы с высоким значением центральности являются наиболее загруженными логистическими центрами. В отличие от степени узла (количества ребер, инцидентных вершине), понятие центральностиузла отражает топологию всей сети.
Вы можете ознакомиться с дополнительными материалами по данной тематике в работе И.А. Евина: [“Введение в теорию сложных сетей”].
Таким образом, для вычисления центральности необходимо выполнить подсчет количества кратчайших путей, проходящих через каждую вершину. Это может быть выполнено с помощью перебора всех стартовых вершин для алгоритма Дейкстры, представленного в предыдущем разделе.
Центральность()
ЦИКЛ ПОКА
Для всех u ∈ V
btwc[u] = 0;
ВСЕ ЦИКЛ ПОКА
ЦИКЛ ПОКА
Для всех u ∈ V
Дейкстра(u);
ЦИКЛ ПОКА
Для всех v ∈ V , v /= u
ЕСЛИ (кратчайший путь (u,v) проходит через вершину k) TO
btwc[k] = btwc[k] + 1;
ВСЕ ЕСЛИ
ВСЕ ЦИКЛ
ВСЕ ЦИКЛ ПОКА
Указанный алгоритм определения центральности представлен в файле dijkstra.c.
//-------------------------------------------------------------
// Центральность
//-------------------------------------------------------------
void btwc () {
//Iterate u
for (Graph::virtex_t u : virtex_range{G1}) {
//Start Dijksra shortest path search
dijkstra_core(u);
//Iterate v
for (Graph::virtex_t v : virtex_range{G1}) {
//For undirected graphs needs to route 1/2 shortest paths (u<v)
if (u != v) {
auto du = G1.search(Graph::Path_key{.u = v}).value().du;
//If there is a route to u
if (du != INF) {
//Get pu
auto pu = G1.search(Graph::Base_key{.u = v}).value().pu;
while (pu != u) {
//Get btwc
auto [du, btwc] = G1.search(Graph::Path_key{.u = pu}).value();
//Write btwc, set du by the way
G1.ins_async(Graph::Path_key{.u = pu}, Graph::Shortest_path{.du = du, .btwc = btwc + 1});
//Route shortest path
pu = G1.search(Graph::Base_key{.u = pu}).value().pu;
}
}
}
}
//Init graph again
for (Graph::virtex_t v : virtex_range{G1}) {
//Init graph again
auto adj_c = G1.search(Graph::Base_key{.u = v}).value().adj_c;
G1.ins_sync(Graph::Base_key{.u = v}, Graph::Attributes{.pu = v, .eQ = true, .non = 0, .adj_c = adj_c});
auto btwc = G1.search(Graph::Path_key{.u = v}).value().btwc;
G1.ins_sync(Graph::Path_key{.u = v}, Graph::Shortest_path{.du = INF, .btwc = btwc});
}
}
}
Пример работы алгоритма для графа-решетки показан на следующем рисунке:
Центральность продемонстрирована с помощью размера и цвета вершины.
4.4.3. Алгоритмы поиска сообществ
Наличие сообществ являются свойством многих сетей, для которых находятся подмножества тесно связанных вершин. В общем случае вершины могут находиться одновременно в нескольких сообществах.
Для оценки целесообразности объединения вершин в сообщества используется числовая характеристика, которая описывает выраженность структуры сообществ в данном графе, и называемая модулярностью:
где δ(Ci, Cj) — дельта-функция, равная единице, если Ci = Cj и нулю иначе.
Физический смысл модулярности состоит в следующем. Возьмём две произвольные вершины i и j. Вероятность появления ребра между ними при генерации случайного графа с таким же количеством вершин и рёбер, как у исходного графа, равна didj/2m. Реальное количество рёбер в сообществе C будет равняться Σi,j ∈ C Ai,j.
Таким образом, модулярность равна разности между долей рёбер внутри сообщества при данном разбиении и долей рёбер в том случае, если бы ребра соединяли вершины случайным образом. Поэтому, метрика модулярности показывает выраженность сообществ (случайный граф структуры сообществ не имеет). Также стоит отметить, что модулярность равна 1 для полного графа, в котором все вершины помещены в одно сообщество, и равна нулю для разбиения на сообщества, при котором каждой вершине сопоставлено по отдельному сообществу. Для особо неудачных разбиений модулярность может быть отрицательной.
4.4.3.1. Выделение сообществ на основе алгоритма MultiLevel
Алгоритм основан на оптимизации модулярности. В начале работы алгоритма каждой вершине сначала ставится в соответствие по сообществу. Далее чередуются следующие этапы:
-
Первый этап
-
Для каждой вершины перебираем её соседей
-
Перемещаем в сообщество соседа, при котором модулярность увеличивается максимально
-
Если перемещение в любое другое сообщество может только уменьшить модулярность, то вершина остаётся в своём сообществе
-
Последовательно повторяем, пока какое-либо улучшение возможно
-
-
Второй этап
-
Создать метаграф из сообществ-вершин. При этом рёбра будут иметь веса, равные сумме весов всех рёбер из одного сообщества в другое или внутри сообщества (т.е. будет взвешенная петля)
-
Перейти на первый этап для нового графа
-
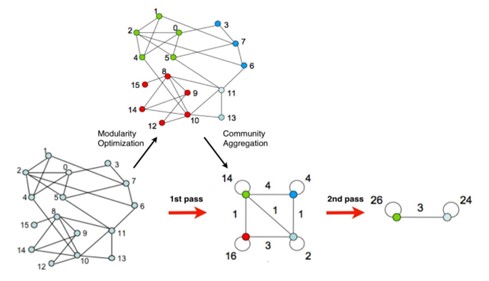
Работа алгоритма Multilevel: два прохода, для первого показаны оба этапа
Алгоритм прекращает работу, когда на обоих этапах модулярность не поддаётся улучшению. Все исходные вершины, которые входят в финальную метавершину, принадлежат одному сообществу.
4.4.3.2. Центральность ребер (Edge Betweenness) – метод Girvan – Newman
Для каждой пары вершин связного графа можно вычислить кратчайший путь, их соединяющий. Будем считать, что каждый такой путь имеет вес, равный 1/N, где N — число возможных кратчайших путей между выбранной парой вершин. Если такие веса посчитать для всех пар вершин, то каждому ребру можно поставить в соответствие значение Edge betweenness — сумму весов путей, прошедших через это ребро.
Для ясности приведём следующую иллюстрацию:
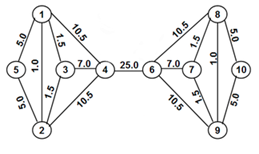
Граф, для ребёр которого посчитаны значения Edge betweenness
В данном графе можно выделить два сообщества: с вершинами 1-5 и 6-10. Граница же будет проходить через ребро, имеющее максимальный вес (25). На этой идее и основывается алгоритм: поэтапно удаляются ребра с наибольшим весом, а оставшиеся компоненты связности объявляем сообществами. Алгоритм состроит из 6 этапов:
-
Инициализировать веса
-
Удалить ребро с наибольшим весом
-
Пересчитать веса для ребёр
-
Сообществами считаются все компоненты связности
-
Подсчитать модулярность
-
Повторять шаги 2-6, пока есть рёбра
4.4.4. Алгоритмы раскладки графов
Раскладка неориентированных графов испольуется при проектировании топологии СБИС, целью которого является оптимизация схемы для получения наименьшего количества пересечений линий. Eades (1984) ввел модель Spring-Embedder, в которой вершины в графе заменяются стальными кольцами, а каждое ребро заменяется пружиной. Пружинная система запускается со случайным начальным состоянием, и вершины соответственно перемещаются под действием пружинных сил. Оптимальная компоновка достигается за счет того, что энергия системы сводится к минимуму.
Эта интуитивная идея была развита Камада и Каваи (1989), Фрухтерман и Рейнгольд (1991) в соответствующих алгоритмах.
4.4.4.1. The Spring Model
Модель spring-embedder была первоначально предложена Eades (1984) и в настоящее время является одним из самых популярных алгоритмов для рисования неориентированных графов с прямолинейными ребрами, широко используемого в системах визуализации информации.
Алгоритм Идеса следует двум эстетическим критериям: равномерная длина ребер и максимально возможная симметрия. В модели Spring-Embedder вершины графа обозначаются набором колец, и каждая пара колец соединена пружиной. Пружина связана с двумя видами сил: силами притяжения и силами отталкивания, в зависимости от расстояния и свойств соединительного пространства.
Раскладка графа приближается к оптимальной по мере уменьшения энергии пружинной системы. К узлам, соединенным пружиной, приложена сила притяжения (fa), а к разъединенным узлам приложена сила отталкивания (fr). Эти силы определяются следующим образом:
ka и kr — константы, а d — текущее расстояние между узлами. Для соединенных узлов это расстояние d является длиной пружины. Начальная компоновка графа настраивается случайным образом. В каждой итерации силы рассчитываются для каждого узла, и узлы соответственно перемещаются, чтобы уменьшить напряжение. Однако модель Spring-Embedder может не работать на очень больших графах.
4.4.4.2. Local Minimum
Модель spring-embedder привела к созданию ряда модифицированных и расширенных алгоритмов раскладки неориентированных графов. Например, силы отталкивания обычно вычисляются между всеми парами вершин, а силы притяжения могут быть рассчитаны только между соседними вершинами. Упрощенная модель уменьшает временную сложность: вычисление сил притяжения между соседями выполняется за O(|E|), хотя вычисление силы отталкивания выполняется за O(|V|²), что в является недостатком алгоритмов с n телами. Камада и Каваи (1989) представили алгоритм, основанный на модели пружинного внедрения Идса, который пытается достичь следующих двух критериев или эвристик рисования графа:
-
Количество пересечений ребер должно быть минимальным.
-
Вершины и ребра распределены равномерно.
Цель алгоритма состоит в том, чтобы найти локальный минимум энергии в соответствии с вектором градиента σ = 0, что является необходимым, но не достаточным условием глобального минимума энергии. С точки зрения вычислительной сложности, такой поиск требует большого количества операций, поэтому в реализацию часто включаются дополнительные элементы управления, чтобы гарантировать, что пружинная система не окажется в локальном минимуме.
В отличие от алгоритма Идеса, который явно не включает закон Гука, алгоритм Камады и Каваи перемещает вершины в новые положения по одной, так что общая энергия пружинной системы уменьшается с новой конфигурацией. Он также вводит понятие желаемого расстояния между вершинами на визуализации: расстояние между двумя вершинами пропорционально длине кратчайшего пути между ними.
Для динамической системы из n частиц, соединенных между собой пружинами, пусть p1, p2 … pn будут частицами в области поля визуализации, соответствующими вершинам v1, v2 … vn V графа соответственно. Сбалансированное расположение вершин может быть достигнуто с помощью динамически сбалансированной пружинной системы. Камада и Каваи сформулировали степень дисбаланса как общую энергию пружин:
Данная модель подразумевает, что наилучшее расположение графа — это состояние с минимальным значением E. Расстояние dij между двумя вершинами vi и vj в графе определяется как длина кратчайшего пути между vi и vj. Алгоритм направлен на согласование длины пружины lij между частицами pi и pj с кратчайшим расстоянием пути, чтобы достичь оптимальной длины между ними на чертеже. Длина lij определяется следующим образом:
где L — желаемая длина одного ребра в области рисования. L можно определить на основе наибольшего расстояния между вершинами в графе. Если L0 — длина стороны квадрата области рисования, L можно получить следующим образом:
Сила пружины, соединяющей pi и pj, обозначается параметром kij:
Затем алгоритм ищет визуальное положение для каждого узла v в топологии сети и пытается уменьшить функцию энергии во всей сети. То есть алгоритм вычисляет частные производные для всех узлов топологии сети с точки зрения каждого xv и yv, которые равны нулю (т.е. ∂E / ∂xv = ∂E / ∂yv = 0; 1 < v < n).
Однако эти нелинейные уравнения зависимы, поэтому для решения задачи можно использовать итерационный подход, основанный на методе Ньютона-Рафсона. На каждой итерации алгоритм выбирает узел m с наибольшим максимальным изменением (Δm). Другими словами, узел m перемещается в новое положение, где он может достичь более низкого уровня Δm, чем раньше. Между тем, другие узлы остаются фиксированными. Максимальное изменение (Δm) рассчитывается следующим образом:
4.4.4.3. Force-Directed Placement
Алгоритм Фрухтермана-Рейнгольда основан на модели пружинного встраивания Идса. Он равномерно распределяет узлы, минимизируя пересечения ребер, а также поддерживает одинаковую длину ребер. В отличие от алгоритма Камада-Каваи, алгоритм Фрухтермана-Рейнгольда использует две силы (силы притяжения и силы отталкивания) для обновления узлов, а не использует функцию энергии с теоретическим графическим расстоянием.
Сила притяжения (fa) и сила отталкивания (fr) определяются следующим образом:
где d — расстояние между двумя узлами, а k — константа идеального попарного расстояния. Константа идеального расстояния k = √(area / n). Здесь area — область рамки чертежа, n — общее количество узлов в топологии сети.
Алгоритм Фрухтермана-Рейнгольда выполняется итеративно, и все узлы перемещаются одновременно после расчета сил для каждой итерации. Алгоритм добавляет атрибут «смещения» для контроля смещения положения узлов. В начале итерации алгоритм Фрухтермана-Рейнгольда вычисляет начальное значение смещения для всех узлов с использованием силы отталкивания (fr). Алгоритм также использует силу притяжения (fa) для многократного обновления визуального положения узлов на каждом ребре. Наконец, он обновляет смещение положения узлов, используя значение смещения.
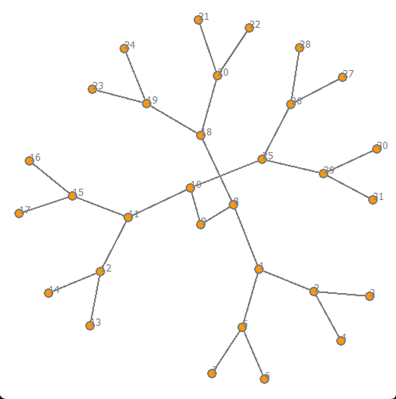
Раскладка графа Local minmum - Kamada - Kawaii
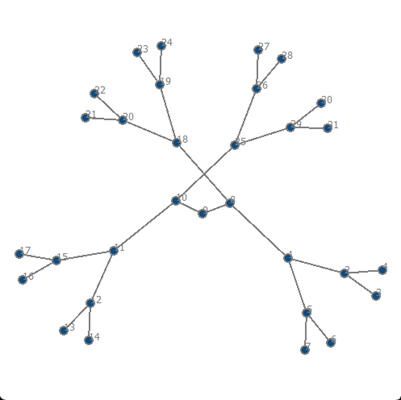
Раскладка графа Force-directed layout - Fruchterman - Reingold
4.5. Сборка и запуск проекта
После подключения к серверу по протоколу ssh необходимо клонировать репозиторий git с кодом примера. Для этого выполните команду:
git clone --recursive https://gitlab.com/leonhard-x64-xrt-v2/btwc-example/btwc-dijkstra-xrt.git
Для сборки проекта перейдите в директорию disc-example и выполните команду make:
cd btwc-dijkstra-xrt
make
Результатом выполнения команды станет файлы host_main, sw_kernel_main.rawbinary и leonhard_2cores_267mhz.xclbin в директории проекта верхнего уровня.
Для запуска проекта выполните команду
./host/host_main leonhard_2cores_267mhz.xclbin ./sw-kernel/sw_kernel.rawbinary
Для выбора варианта раскладки графа необходимо указать в файле ./host/src/host_main.cpp один из вариантов:
- Разсладка сообществ с помощью иерархического объединения и укладки в боксы:
#define BOX_LAYOUT //#define FORCED_LAYOUT
или
- Раскладка сообществ с помощью силового алгоритма Фрухтермана-Рейнгольда:
//#define BOX_LAYOUT
#define FORCED_LAYOUT
Если устройство занято другим проектом, вы можете сбросить его командой
xbutil reset!
Отказ запуска при блокировке карты
Если устройство не было разблокировано, это означает, что один из пользователей не остановил процесс отладки по
dgb. Вы можете остановить все отладчики в системе и сбросить карту командойsudo /opt/xilinx/overlaybins/reset.sh(даже несмотря на то, что вы не являетесь членом группы sudoers!!!)
После запуска проекта host будет открыт WebSocket на порту 0x4747.
Group #0 Core #0
Software Kernel Version: 0x0000001a
Leonhard Status Register: 0x00300001_09110611
DISC system speed test v3.0
Start at local date: 02.10.2022.; local time: 13.36.03
Test value units
-------------------------------------------------------------------------------------
Graph Processing Cores count (GPCC) 1 instances
-------------------------------------------------------------------------------------
Leonhard clock frequency (LNH_CF) 240 MHz
-------------------------------------------------------------------------------------
Data graph created!
BTWC is done for 0.00 seconds
Create visualisation
I этап: инициализация временных структур
Количество сообществ в очереди 3580 и в структуре сообществ 213
Количество вершин в графе 213
II этап: выделение сообществ
III этап: построение дерева сообществ
IV этап: выделение прямоугольных областей
V этап: определение координат вершин
Wait for connections
Далее можно запустить сервер bokeh, выполняющий визуализацию графа. Для этого испольщуем команды менеджера консольных окон screen:
- Ctrl-a + c: создает новые окна.
- Ctrl-a + w: отображает список всех открытых в данный момент окон.
- Ctrl-a + A: переименовать текущие окна. Имя появится, когда вы перечислите список окон, открытых с помощью Ctrl-a + w.
- Ctrl-a + n: Переход к следующим окнам.
- Ctrl-a + p: Переход к предыдущим окнам.
- Ctrl-a + Ctrl-a: Возврат к последнему использовавшемуся окну.
- Ctrl-a + k: закрыть текущие окна (убить).
- Ctrl-a + S: разделяет текущие окна по горизонтали. Чтобы переключаться между окнами, сделайте Ctrl-a + Tab.
-
Ctrl-a + : разделяет текущие окна по вертикали. - Ctrl-a + X: закрыть активное разделенное окно.
- Ctrl-a + Q: закрыть все разделенные окна.
- Ctrl-a + d: Отключить сеанс экрана, не останавливая его.
- Ctrl-a + r: повторное подключение отсоединенного сеанса экрана.
- Ctrl-a + [: Запускает режим копирования.
- Ctrl-a +]: вставляет скопированный текст.
Создадим новую консольную сессию окна: Ctrl-a + c
Далее запустим сервер bokeh:
cd <Путь к проекту btwc-example>
cd bokeh
./start_33000.sh btwc.py
В итоге будет получена ссылка на визуализацию случайного графа:
Starting Bokeh server version 2.4.3 (running on Tornado 6.1)
User authentication hooks NOT provided (default user enabled)
Bokeh app running at: http://195.19.32.95:33000/btwc
Starting Bokeh server with process id: 65483
Если копия сервера уже запущена на данном порту 33000, то вы можете указать в файле start_33000.sh другой свобобный порт.
Starting Bokeh server version 2.4.3 (running on Tornado 6.1)
Cannot start Bokeh server, port 33000 is already in use
Укажем порт 33001 и перезапустим сервер:
./start_33000.sh btwc.py
В результате по указанной ссылке будет визуализирован случайный граф:
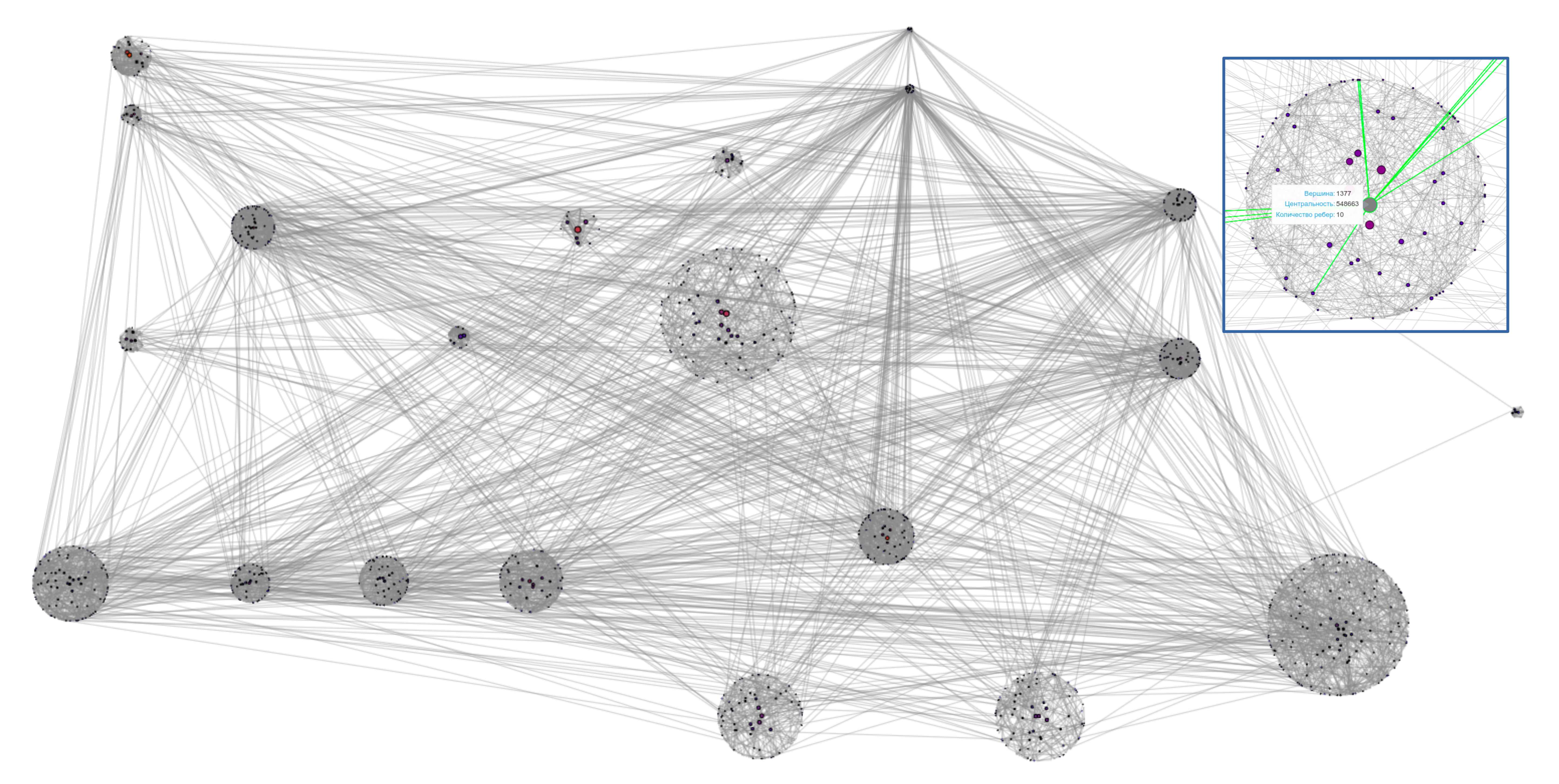 Результат визуализации графа с использование Центральности, Выделения сообществ и раскладки с помощью алгоритма гельотинного деления
Результат визуализации графа с использование Центральности, Выделения сообществ и раскладки с помощью алгоритма гельотинного деления
4.6. Индивидуальные задания
Выполнить визуализацию неориентированного графа, представленного в формате tsv. Каждая строчка файла представляет собой описание ребра, сотоящее из трех чисел (Вершина,Вершина,Вес) или двух чисел (Вершина,Вершина). Во втором случае вес ребра принимается равным 1.
Вариант 1
Визуализация графа: Файл данных kronecker_var01
Вариант 2
Визуализация графа: Файл данных kronecker_var02
Вариант 3
Визуализация графа: Файл данных kronecker_var03
Вариант 4
Визуализация графа: Файл данных kronecker_var04
Вариант 5
Визуализация графа: Файл данных kronecker_var05
Вариант 6
Визуализация графа: Файл данных kronecker_var06
Вариант 7
Визуализация графа: Файл данных kronecker_var07
Вариант 8
Визуализация графа: Файл данных kronecker_var08
Вариант 9
Визуализация графа: Файл данных simulated_blockmodel_graph_500_nodes
Вариант 10
Визуализация графа: Файл данных simulated_blockmodel_graph_500_nodes_snowball_1
Вариант 11
Визуализация графа: Файл данных simulated_blockmodel_graph_500_nodes_snowball_2
Вариант 12
Визуализация графа: Файл данных simulated_blockmodel_graph_500_nodes_snowball_3
Вариант 13
Визуализация графа: Файл данных simulated_blockmodel_graph_500_nodes_snowball_4
Вариант 14
Визуализация графа: Файл данных simulated_blockmodel_graph_500_nodes_snowball_5
Вариант 15
Визуализация графа: Файл данных simulated_blockmodel_graph_500_nodes_snowball_6
Вариант 16
Визуализация графа: Файл данных simulated_blockmodel_graph_500_nodes_snowball_7
Вариант 17
Визуализация графа: Файл данных simulated_blockmodel_graph_500_nodes_snowball_8
Вариант 18
Визуализация графа: Файл данных simulated_blockmodel_graph_500_nodes_snowball_9
Вариант 19
Визуализация графа: Файл данных simulated_blockmodel_graph_500_nodes_snowball_10
Вариант 20
Визуализация графа: Файл данных simulated_blockmodel_graph_1000_nodes
Вариант 21
Визуализация графа: Файл данных simulated_blockmodel_graph_1000_nodes_snowball_1
Вариант 22
Визуализация графа: Файл данных simulated_blockmodel_graph_1000_nodes_snowball_2
Вариант 23
Визуализация графа: Файл данных simulated_blockmodel_graph_1000_nodes_snowball_3
Вариант 24
Визуализация графа: Файл данных simulated_blockmodel_graph_1000_nodes_snowball_4
Вариант 25
Визуализация графа: Файл данных simulated_blockmodel_graph_1000_nodes_snowball_5
Вариант 26
Визуализация графа: Файл данных simulated_blockmodel_graph_1000_nodes_snowball_6
Вариант 27
Визуализация графа: Файл данных simulated_blockmodel_graph_1000_nodes_snowball_7
Вариант 28
Визуализация графа: Файл данных simulated_blockmodel_graph_1000_nodes_snowball_8
Вариант 29
Визуализация графа: Файл данных simulated_blockmodel_graph_1000_nodes_snowball_9
Вариант 30
Визуализация графа: Файл данных simulated_blockmodel_graph_1000_nodes_snowball_10
Вариант 31
Визуализация графа: Файл данных static_highOverlap_highBlockSizeVar_1000_nodes
Вариант 32
Визуализация графа: Файл данных static_highOverlap_lowBlockSizeVar_1000_nodes
Вариант 33
Визуализация графа: Файл данных static_lowOverlap_highBlockSizeVar_1000_nodes
Вариант 34
Визуализация графа: Файл данных static_lowOverlap_lowBlockSizeVar_1000_nodes
5. Командный практикум. Обработка и визуализация графов в вычислительном комплексе Тераграф
5.1. Пример визуализации корреляционной матрицы в виде графа
Зрительная система человека способна естественным образом обрабатывать многомерную информацию. Например, человек можем обнаружить закономерности на диаграмме рассеяния, приводящие его к выдвижению различных гипотез, в то время как эти же закономерности невидимы, когда данные представлены в виде матрицы.
Матрица корреляции может быть представлена в виде графа, в котором каждая переменная является узлом, а каждая корреляция — ребром. Изменяя отсекающую оценку для ребер в соответствии с величиной корреляции, можно визуализировать структуру матрицы корреляции, наглядно демонстрируя возникающие связанные подмножества переменных. Таким образом можно представить широкий спектр матриц, используемых в статистике, для наглядного представления ковариаций, результатов факторного анализа, регрессии и т.д..
Пример представления корреляционной матрицы вы можете найти в следующей блокноте: Пример блокнота Jupyter Notebook в Google Colab
Представленная в примере предметная область позволяет оценить биологический возраст человека по серии измерений (частота сердечных сокращений, частота дыхания, длительность нахождения в позе Ромберга и т.д.). Полученный граф позволяет быстро обнаружить аномалии в измеренных параметрах и наглядно представить их. Пояснения терминологии, используемой при анализе биологического возраста, вы можете найти в файле глоссария.
Граф знаний, представляющий корреляционную матрицу на основе отсекающей оценки коэффициента корреляции, может быть использован для анализа физиологического состояния человека
Для анализа результатов полезно представить корреляционную матрицу:
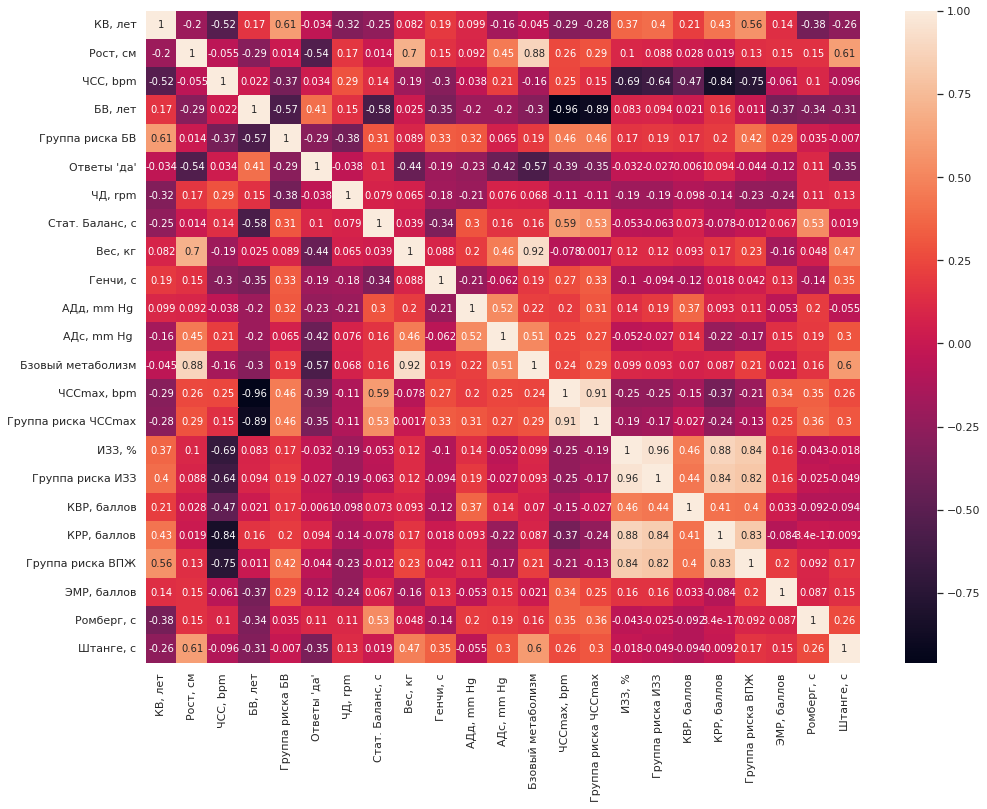
Далее может быть задана отсекающая оценка коэффициента корреляции (например, на основе p-значения или уровня значимости alpha, или используя экспертную оценку для визуализации требуемого порога корреляции).
В итоге получаем графы, демонстрирующие матрицу корреляции в наглядной форме:
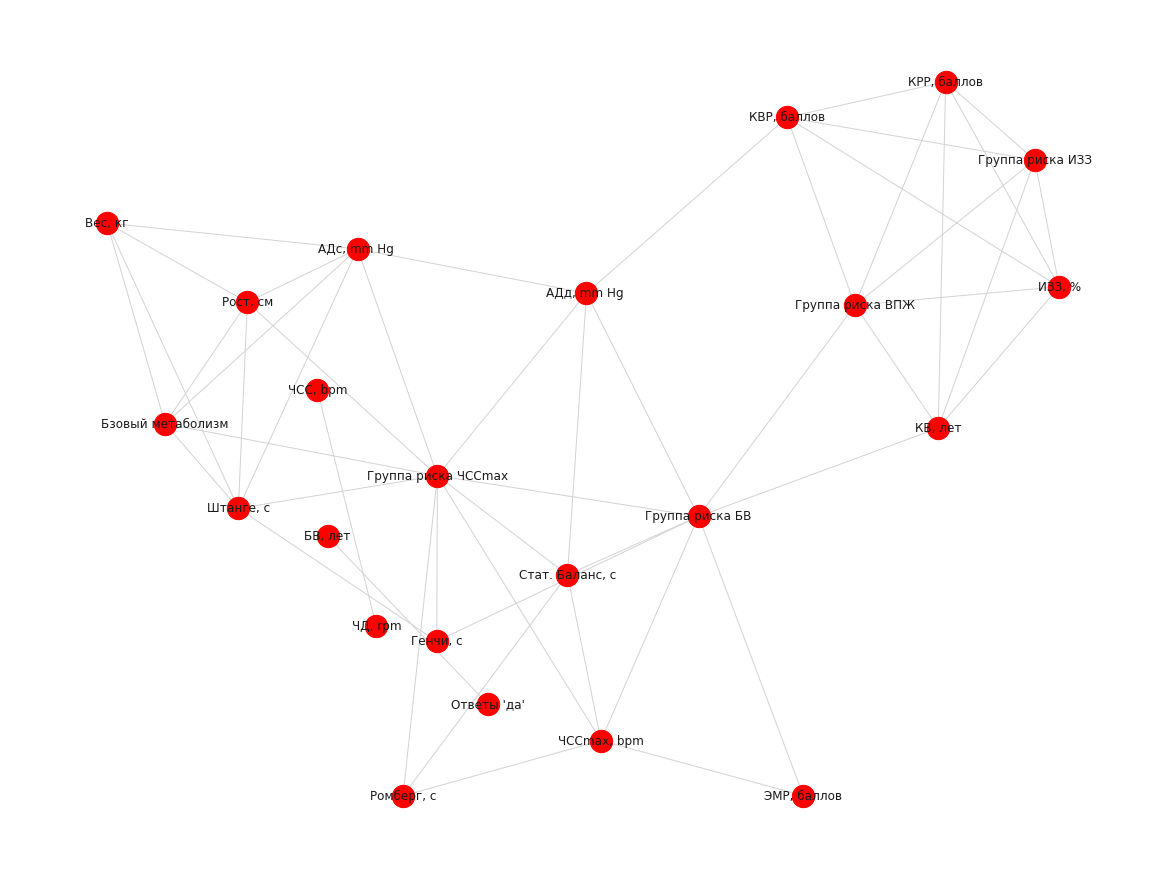
5.2. Задание практикума
Необходимо предложить варианты применения графов для решения важных задач. Для выбранной задачи необходимо найти примеры исходных данных и визуализировать их в виде графа. Для визуализации могут быть использованы любые из перечисленных ресурсов:
-
Вычислительный комплекс Тераграф.
-
Скрипты python в виде ноутбуков в локальном или облачном варианте (Kaggle,Google Colab и др.).
-
Средства визуализации графов в локальном или облачном варианте
В результате практикума команда должна представить краткое описание идеи (тема, актуальность, краткое описание) и визуализацию данных в виде изображения с высоким разрешением.
Изображение будет распечатано организаторами конкурса и будет представлять проект на защите.
Конкурсные работы
Граф решетки
Изображен граф решетки. Цвет и размер вершин определяется их центральностью
Гипотеза_Колатца
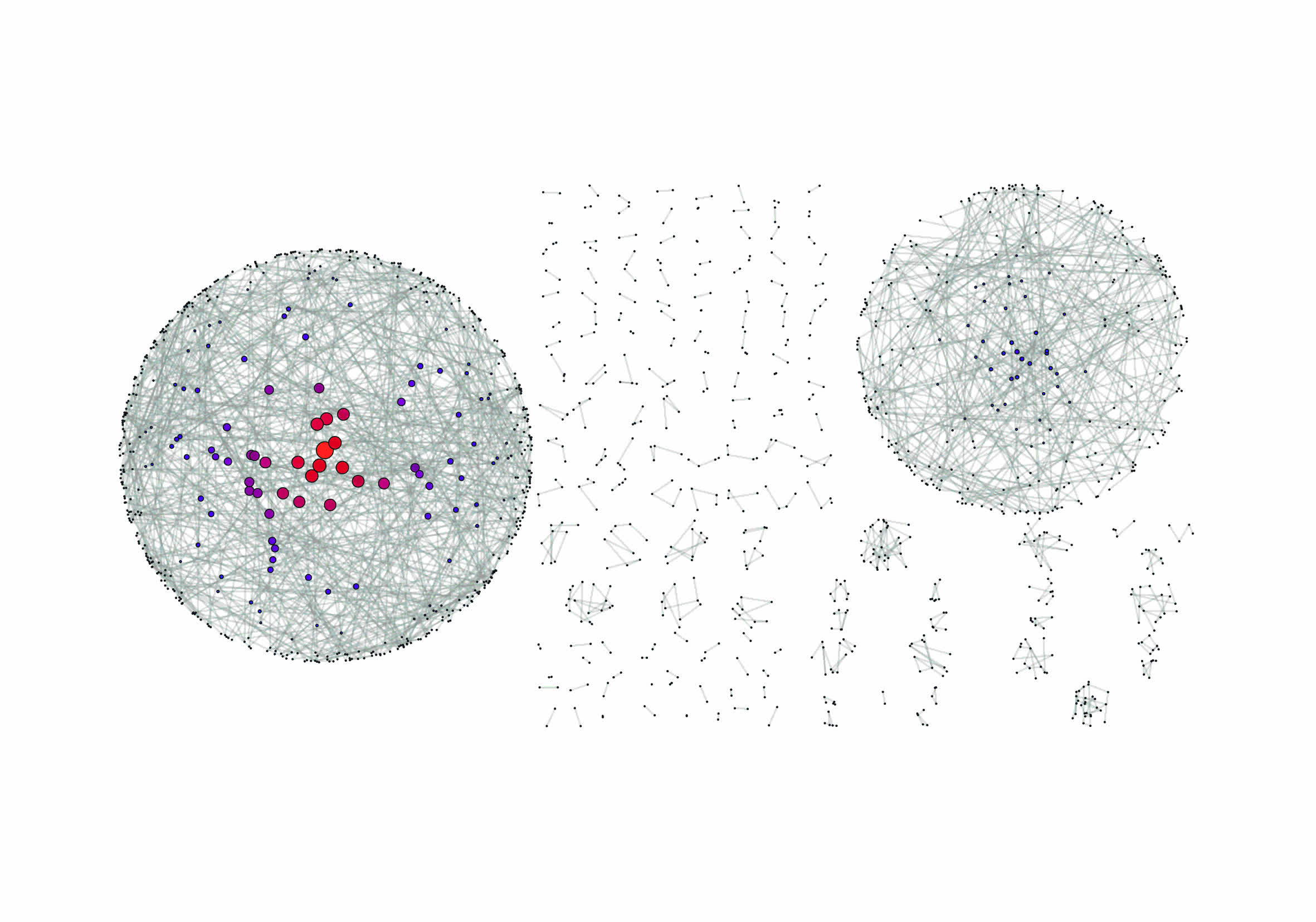
Гипотеза Коллатца (3n+1 дилемма, сиракузская проблема) — одна из нерешённых проблем математики. Показан граф, демонстрирующий последовательности первых 2000 чисел.
Сообщества патентных классов
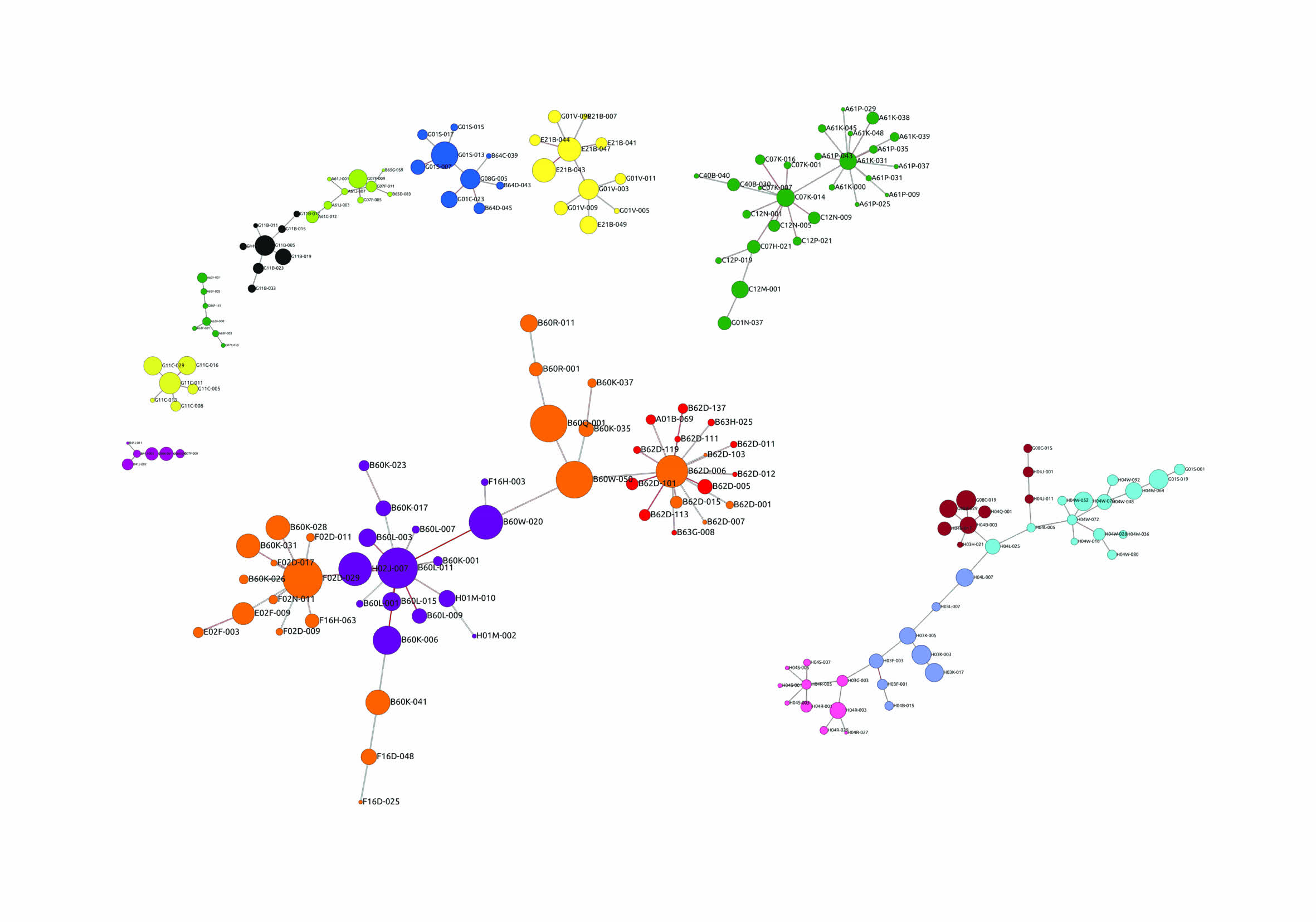
Изолированные графы - это крайне слабо связанные группы («надсообщества») патентных классов, ребра между которыми были отфильтрованы как шум. Цвет вершины - выражает принадлежность патентного класса к выделенному сообществу. Размер вершины - количество патентов в данном классе. Цвет (степень красноты) ребра - его вес.
Вагапоиды

Размер узла (а также его цвет от желтого до красного) - это количество связей у этого человека (красный - разговаривает/дружит/ссорится со многими, желтый - что то типа новичка в коллективе или интроверт). Размер дуги (а так же изменение цвета от светлого до темного серого) - это ““вес отношений””. Чем толще(темнее), тем более дружественные отношения.”
Звезда Смерти
На изображении показана модель данных, представляющая собой туристические поездки россиян в 2022 году. Одинаковые атрибуты различных поездок позволяют связать их в граф. В центрах сообществ находятся наиболее типичные варианты путешествий.
Новогодний лес Левенштейна

На картине изображены новогодние ели, на ветках которых размещены новогодние игрушки - шары. Каждый шар - это слово, а расстояние между словами - расстояние Левенштейна. Было использовано 7 основных слов (по одному на члена команды), для которых искали однокоренные и считали расстояния между всеми парами. Итоговая картинка получена путем связывания ребрами каждой пары основных слов.
Структура модели личности человека
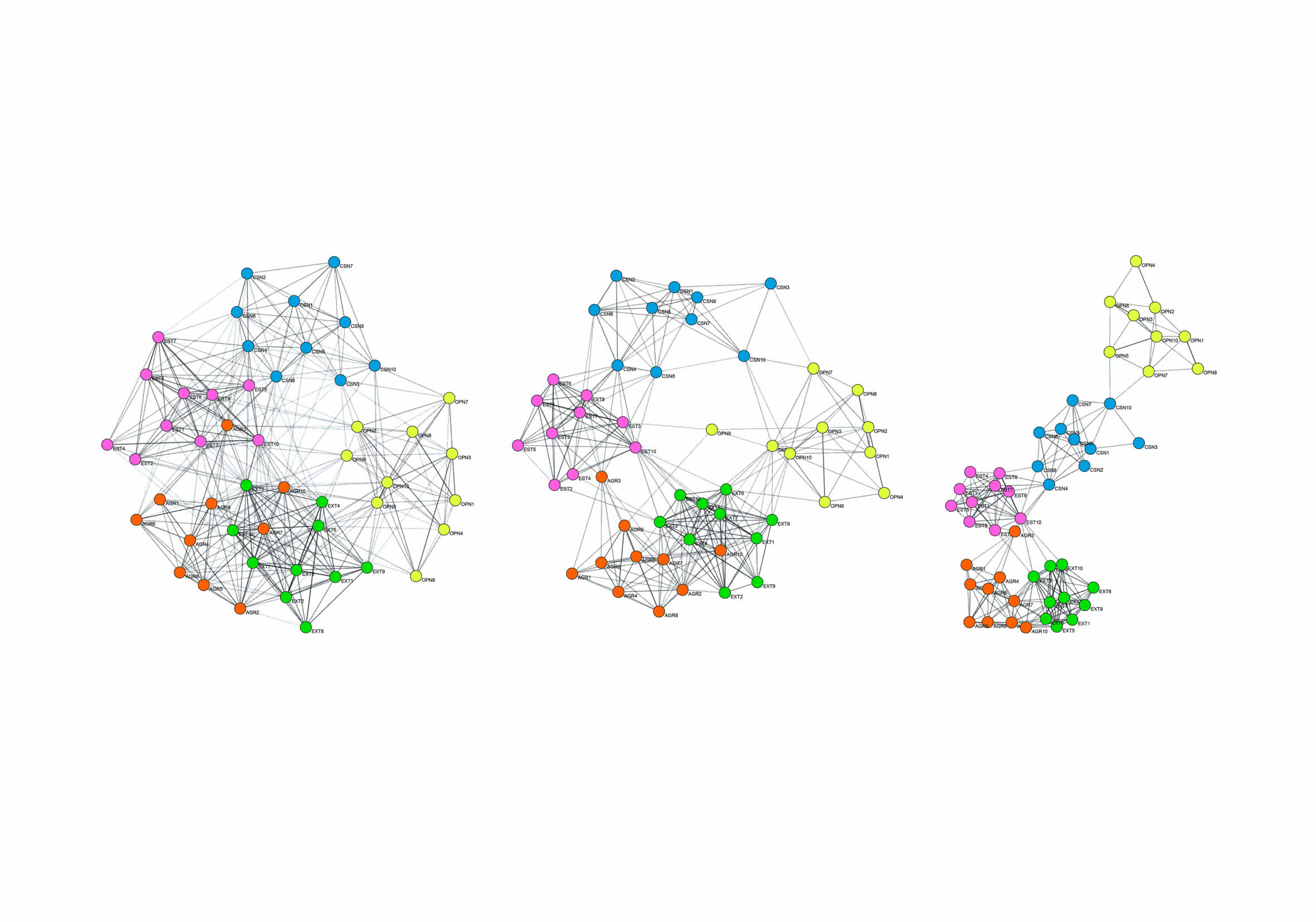
Проанализирована структура личностного теста, основанного на Пятифакторной модели личности. Каждый цвет на графе отвечает за один из факторов: 1) Зеленый - Экстраверсия (общительный/энергичный); 2) Желтый - Открытость опыту (изобретательный/любопытный); 3) Синий - Добросовестность / сознательность (рациональный/организованный); 4) Оранжевый - Доброжелательность (дружелюбный/эмпатичный); 5) Розовый - Эмоциональная стабильность (стойкий/уверенный в себе). Каждая вершина графа соответствует конкретной черте характера, которая относится к соответствующему фактору модели. Чем четче показано ребро – тем больше коэффициент корреляции между чертами. Графы расположены по возрастанию порога коэффициента корреляции.
История развития вселенной

Вершинами в данном графе являются популярные Youtube каналы по запросу “котики”. При запросе в Youtube осуществляется поиск видео по запросу, а затем похожих видео. На основании этого между Youtube каналами ребра отображают наличие похожих видео.
Денежные транзакции

Цвет определяет степень подозрения аккаунта в мошенничестве: красные вершины - мошеннические аккаунты; cиние вершины - посреднические мошеннические аккаунты для заметания следов.
Граф соавторства научных публикаций

Вершины представляют автора, связи - наличие соавторства между авторами. Чем больше по размеру вершина, тем больше публикаций у автора, чем толще связь, тем больше публикаций у данных двух авторов в соавторстве. В центре помещена вершина, представляющая российского ученого в области компьютерных наук Сергея Левина. Подписанные вершины - это недавние авторы, с которыми данный ученый опубликовал работу в соавторстве.
Вселенная адаптационного синдрома Ганса Селье
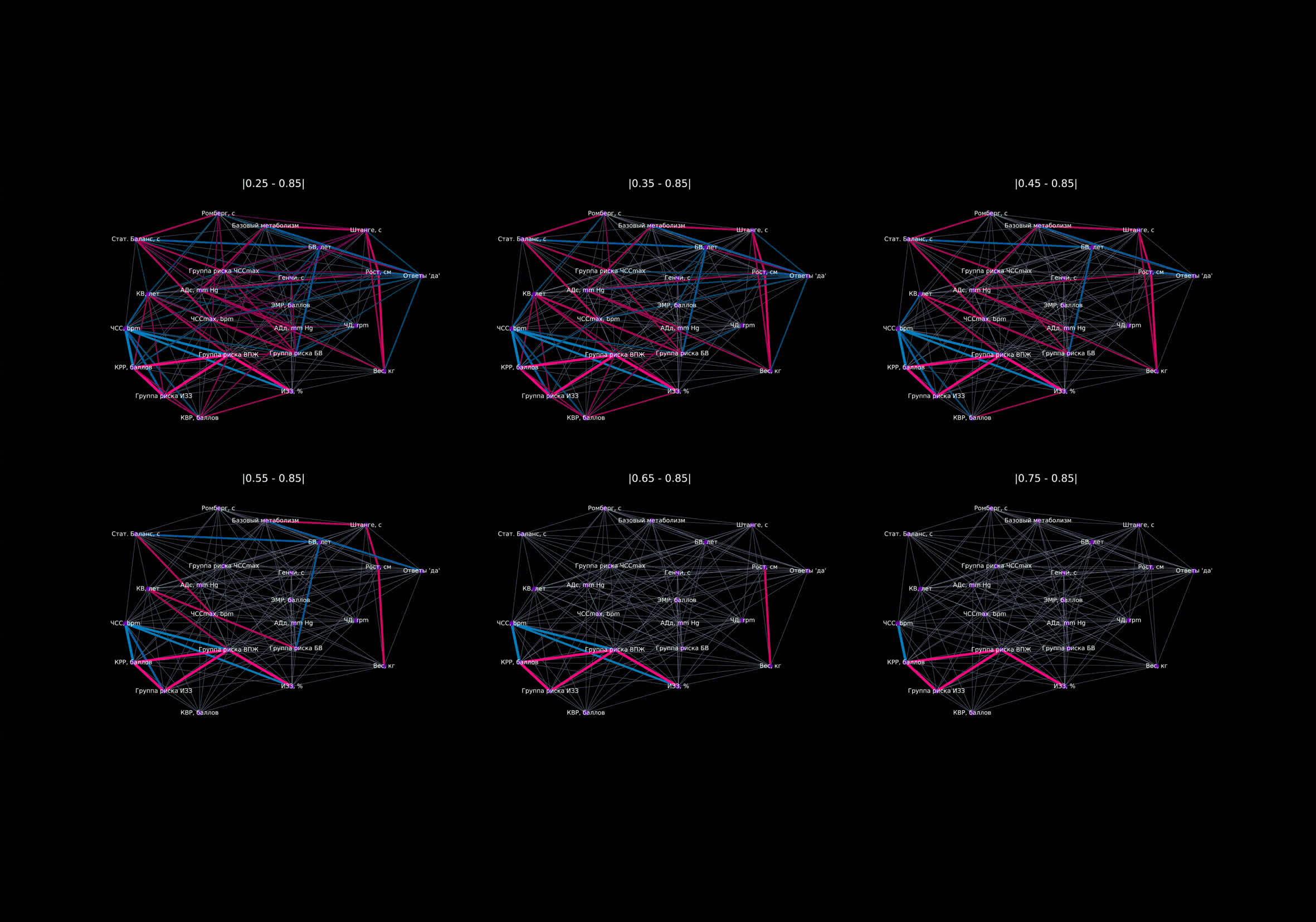
Графы представляют матрицу корреляции физиологических параметров группы людей с различной отсекающей оценкой корреляционной связи. Графы наглядно демонстрируют особенности организма, впервые выявленные Гансом Селье.
Kloube la romantique
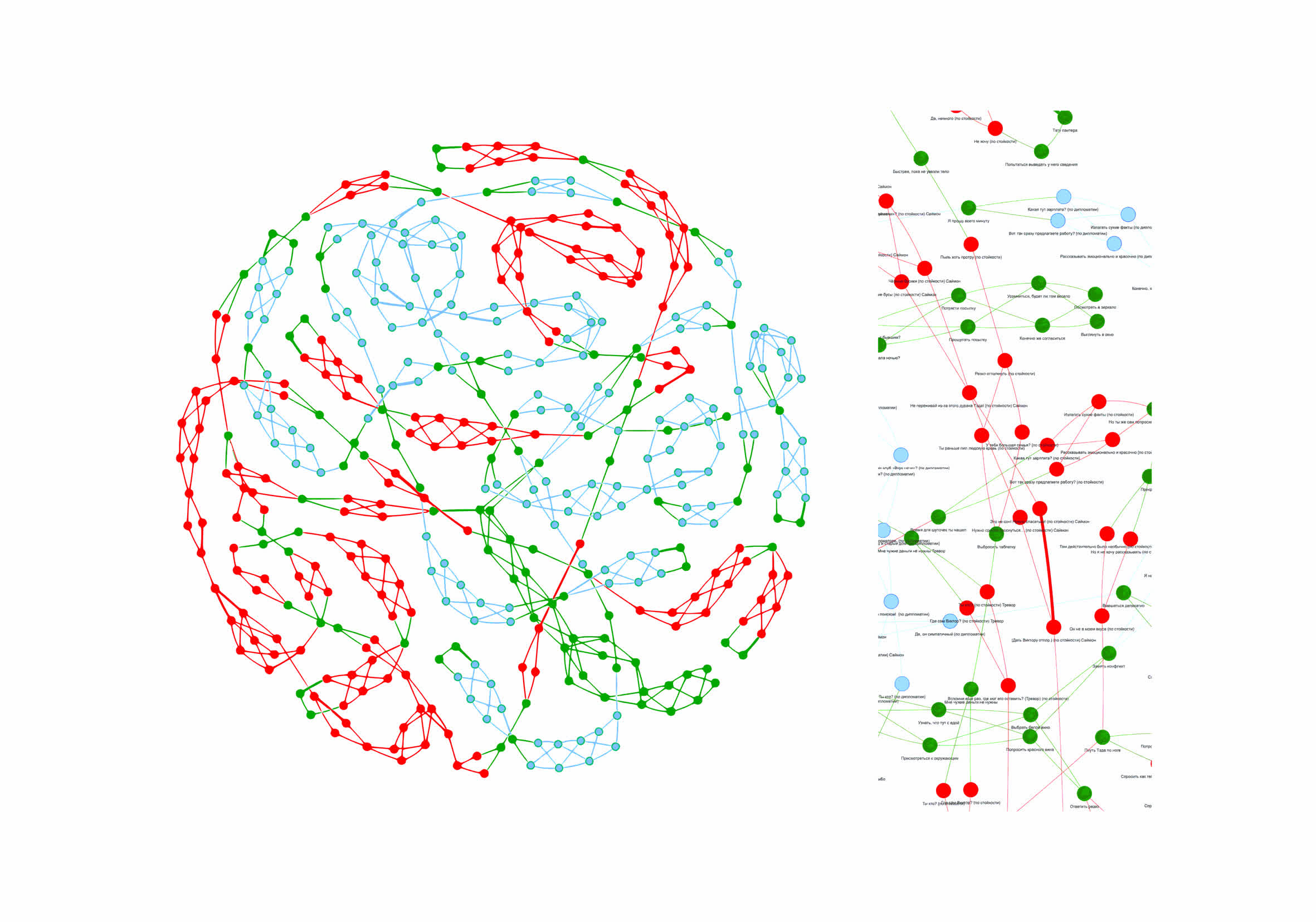
На картине изображен граф визуализации возможных исходов в диалоге. Цветом выделены 3 основные группы выборов: зеленые – не влияющие на исход выборы, красные – выборы сделанные по агрессивной модели поведения, синие – выборы сделанные по дипломатичной модели поведения. Толщина линий означает цену, которую пользователь заплатит за определенный выбор.
Сцена охоты коронавируса
Менее чем за 20 лет в человеческой популяции появились три смертельных коронавируса: SARS-CoV, MERS-CoV и SARS-CoV-2, что привело к гибели от сотен до сотен тысяч человек. Другие коронавирусы вызывают эпизоотии, представляющие значительную угрозу как для домашних, так и для диких животных. Члены этого вирусного семейства имеют самый длинный геном из всех РНК-вирусов и экспрессируют до 29 белков, устанавливающих сложные взаимодействия с протеомом хозяина. Расшифровка этих взаимодействий необходима для выявления клеточных путей, захваченных этими вирусами, для репликации и ухода от врожденного иммунитета. Взаимодействия вирус-хозяин также предоставляют ключевую информацию для выбора целей для разработки противовирусных препаратов. Здесь мы визуализируем набор данных о белок-белковых взаимодействиях коронавирус-хозяин. В визуализации применен метод (кластеризация) Лувена - это метод извлечения сообществ из больших сетей. Метод может находить кластера произвольной формы и избегать воздействий шумов.
Температура финансового рынка
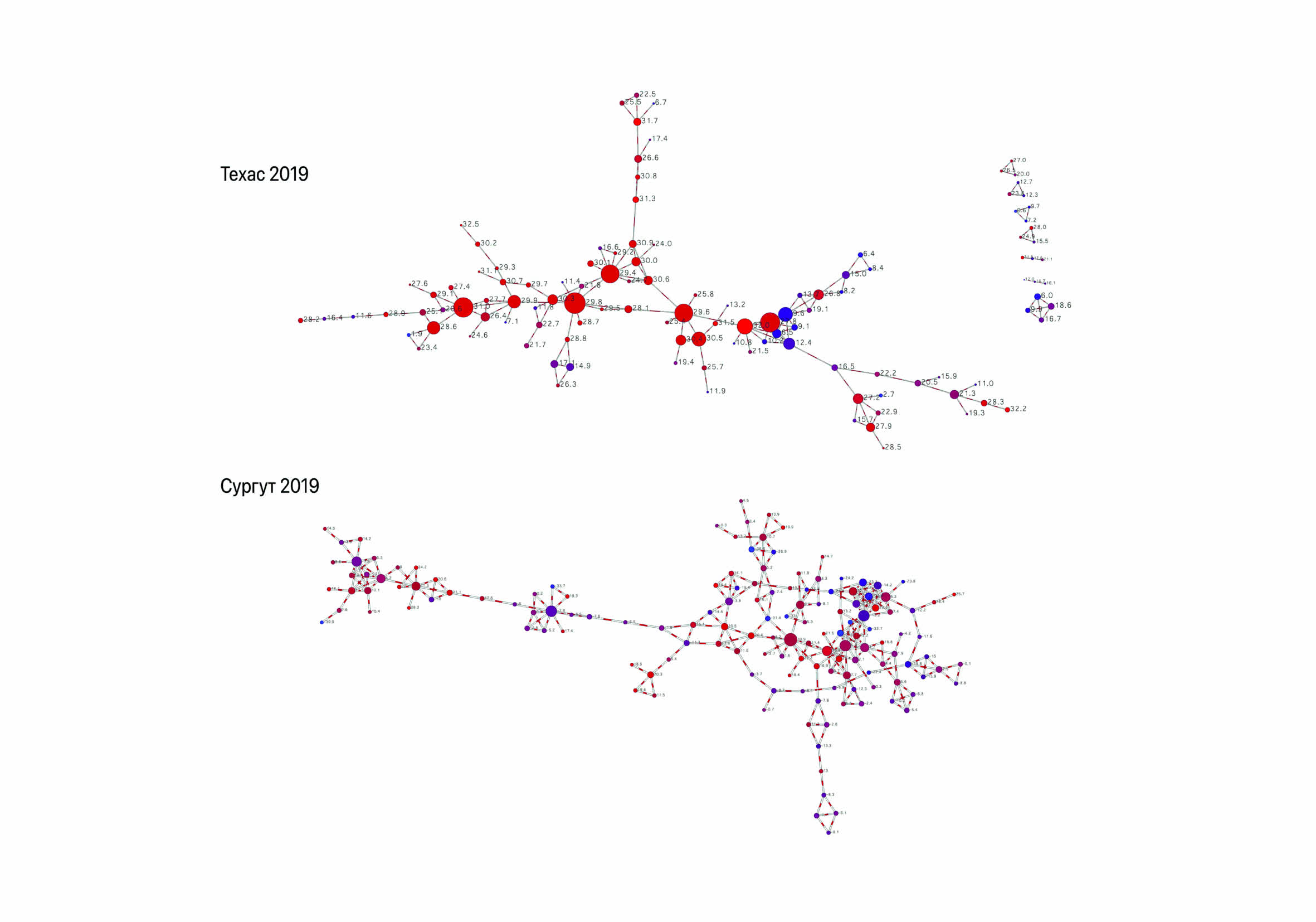
Цвет - температура (горячо/холодно), вершина - температура в какой-то день года, две вершины связаны, если разность цен барреля нефти в соответствующие дни не превышает значения X, где Х - некоторое число. Для 1 графа (Техас) Х = 0,02, то есть 2 цента, для 2 (Сургут) - 0,05.
Доверие

Продемонстрирован граф в котором отображен анализ репутации пользователей на основе оценок выставленных другими пользователями. На графе репутация пользователей отображается при помощи вершин, которые имеют разный цветовой фон - чем темнее фон, тем лучше репутация. Количество ребер для которых исходная вершина является концом, пропорциональны количеству оценок пользователей.
Звездопад

На картине изображена сеть сайтов, связанных между собой гиперссылками. Размеры вершин, а также цвета назначаются в соответствии с центральностью вершины.
Ярославль, социальные связи

Кругами обозначены люди, а линиями - знакомства. Чем больше знакомств у человека, тем больше круг, и тем он ближе к розовому оттенку.
Солнечный Паттерн
Изображен граф найденных сообществ на поверхности солнца, объединенные общей интенсивностью свечения. Цвет вершины обозначает, что она является центральной частью области, которая имеет приблизительно равную интенсивность излучения, на поверхности Солнца. Толщина линий означает степень связности двух точек на поверхности звезды между собой. Удаленность сообществ друг от друга примерно аналогична удаленности этих паттернов на поверхности солнца.
Мы живем в обществе

Для каждого участника сообщества VK МГТУ им. Н.Э.Баумана определяется список сообществ на которые он подписан. При этом связь с общим сообществом игнорируется. Используется дополнительное ограничение на пороговое количество совместных сообществ. Далее применяются алгоритмы кластеризации (алгоритм Лейдена или алгоритм Каргера), чтобы определить, на какие подсообщества разбиты участники. Вершина - конкретный человек, связь - взаимная подписка на одни и те же сообщества, и разбитые с помощью цветов подсообщества.
Связь между документами
Узлами графа являются имена документов. Если какой-то из файлов ссылается на другой, между их именами образуется однонаправленное ребро. Размер узла зависит от количества входящих в него ребер (количества ссылающихся на него файлов), чем больше ребер, тем больше размер узла.
Одуванчики

На картине изображён результат применения графовой нейронной сети для решения задачи классификации. Вершины одного цвета принадлежат одному кластеру, т. е. образуют сообщество, внешне похожее на одуванчик.
Colloquium_Cum_Comes

Вершины расположены по алфавиту, их размер определяется тем, сколько раз они попадаются в более чем 1,5М выборке русских слов. Толщина связей определяется тем, сколько раз был осуществлен переход между этими буквами. Цвет случаен
Аномалии в отзывах
Предлагается анализировать граф, описывающий отношения между рецензентом, отзывом и рецензируемым объектом (товаром, услугой). Таким образом, граф содержит три типа узлов. Узел рецензента (зелёный) имеет связь с узлом рецензии (красный), узел рецензии — с узлом объекта (синий). Предлагается присваивать рецензентам показатели «степени доверия им», их обзорам — показатель «достоверности», а объектам — показатель «надежности». Все эти показатели взаимосвязаны. Уровень доверия к рецензенту зависит от того, насколько у него достоверные рецензии. Надежность рецензируемых объектов зависит от степени доверия рецензентам, которые его описывают, а достоверность обзоров зависит от надежности товара, по которым они пишутся, и от доверия их авторам. Величины этих показателей выражены в размерах узлов. Обнаружение аномалий в таком графе может позволить обнаруживать спам-обзоры.
Универы
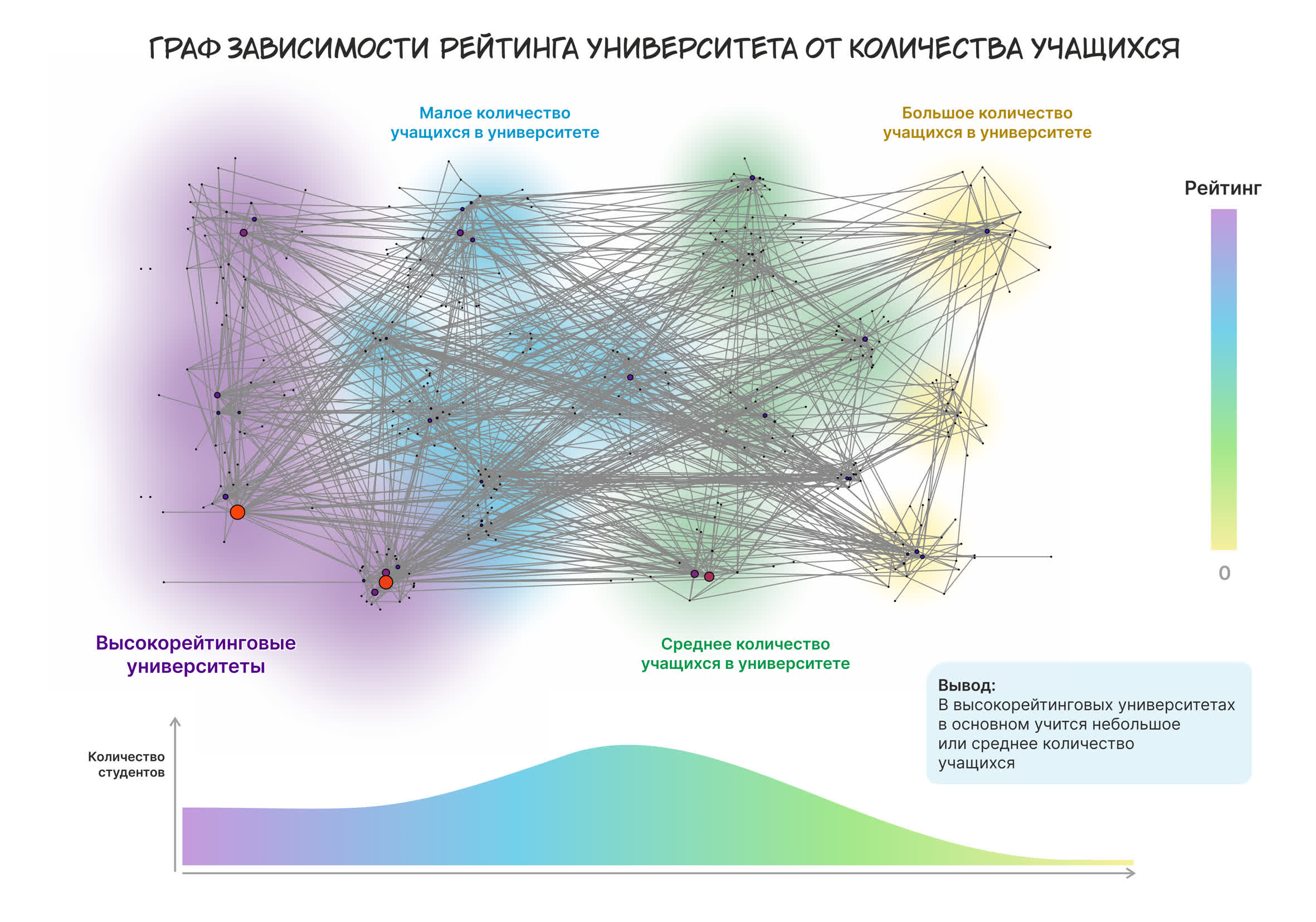
Представлены университеты, обладающие атрибутами: уровень рейтинга и количество студентов. Связи образуются при совпадении параметров. По графу можно сделать вывод что в университетах с самыми высокими рейтингами по их странам больше учится небольшое или среднее количество студентов, так как левая и средняя часть более плотная.